import pickle
import theano
import pandas as pd
import numpy as np
import pymc3 as pm
import arviz as az
import seaborn as sns
import multiprocessing as mp
from theano import tensor as tt
from matplotlib import pyplot as plt
from threadpoolctl import threadpool_limits
from datetime import datetime2 Hierarchical Bayesian Models to describe differences in isotopic values between and within species
2.1 Imports
2.1.1 Miscelaneous configurations
%env THEANO_FLAGS=device=cpu,floatX=float32
%env OMP_NUM_THREADS=1
#%env MKL_NUM_THREADS=1
%config InlineBackend.figure_format = 'retina'env: THEANO_FLAGS=device=cpu,floatX=float32
env: OMP_NUM_THREADS=1plt.rcParams['font.family'] = 'Serif'
colors = plt.rcParams['axes.prop_cycle'].by_key()['color']
plt.rcParams['font.size'] = 12
output_dir = 'output/HBGLM'2.2 Exploratory Data Analyses
Loading the data from the glm.csv file:
# Loading the data and renaming some columns
col_names = {'sexo': 'Sex',
'temporada': 'Season',
'estadio':'Maturity',
'sp': 'Species',
'year': 'Year'}
# Drop unused columns and missing data
glm_data = pd.read_csv('data/glm.csv').rename(columns = col_names).dropna()
# Translating field values to spanish keys
glm_data.Sex = glm_data.Sex.map({'M':'Male', 'H': 'Female'})
glm_data.Season = glm_data.Season.map({'Calida': 'Warm', 'Fria': 'Cold'})
glm_data.Maturity = glm_data.Maturity.map({'Adulto': 'Adult', 'Juvenil': 'Juvenile'})
# Copy of the original dataset, before coding any dummy variables
ref_data = glm_data.copy()
# Preview of the data
glm_data.head()| Species | Year | Season | Sex | Maturity | d15n | d13c | |
|---|---|---|---|---|---|---|---|
| 0 | H.dipterurus | 2015 | Warm | Male | Juvenile | 16.301217 | -14.506785 |
| 1 | H.dipterurus | 2015 | Warm | Female | Juvenile | 16.832374 | -17.810405 |
| 2 | H.dipterurus | 2015 | Warm | Male | Adult | 17.135463 | -15.831434 |
| 3 | H.dipterurus | 2015 | Warm | Female | Juvenile | 13.123093 | -15.965960 |
| 4 | H.dipterurus | 2015 | Warm | Male | Adult | 17.633117 | -16.719438 |
2.2.1 Data description
In Figure 2.1 we can observe that:
There is an isotopic gradient between the three species in both isotopes: R. steindachneri < H. dipterurus < N. entemedor.
This gradient is consistent, to different extents, through the covariates, causing deviations from the statistic normality, especially in multivariate terms.
Some classes are misrepresented in relation to anothers
# Variable coding:
# Sex
n_sex = len(glm_data.Sex.unique()) # Número de categorías (2, evidentemente)
glm_data['Sex'] = pd.Categorical(glm_data['Sex']).codes # Se transforma a 0 y 1
sex_idx = glm_data.Sex.values # Se extraen los identificadores
# Season
n_season = len(glm_data.Season.unique())
glm_data['Season'] = pd.Categorical(glm_data['Season']).codes
sex_idx = glm_data.Season.values
# Age
n_mat = len(glm_data.Maturity.unique())
glm_data['Maturity'] = pd.Categorical(glm_data['Maturity']).codes
sex_idx = glm_data.Maturity.values_ = sns.pairplot(glm_data, hue = 'Species', palette = colors[0:3], corner = False)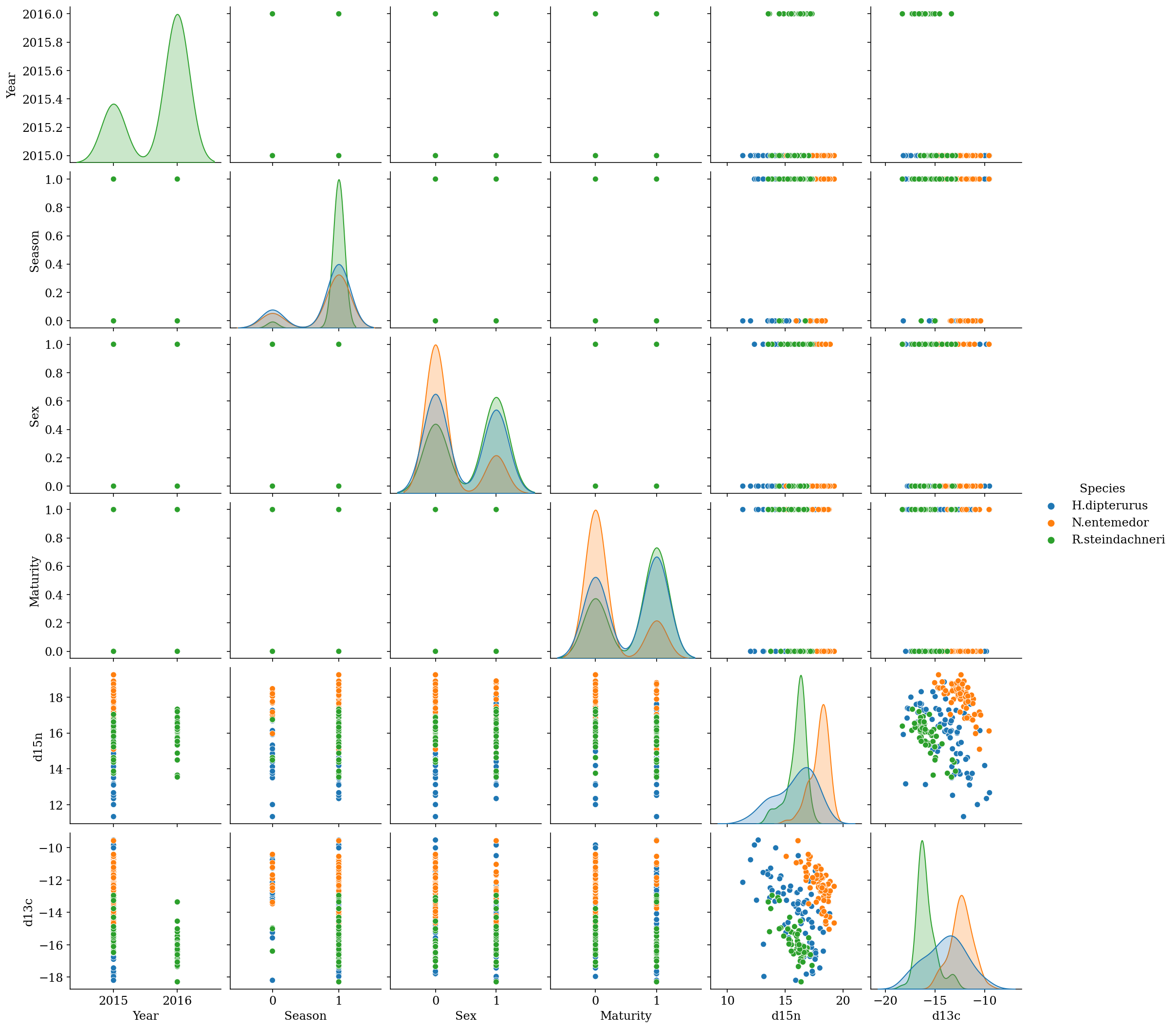
It is important to mention that the year variable has two levels only for R. steindachneri and will, hence, be discarded from the analysis. The sample sizes per species-class pair are:
ref_data.groupby('Species').agg({'d13c': 'count'})| d13c | |
|---|---|
| Species | |
| H.dipterurus | 81 |
| N.entemedor | 69 |
| R.steindachneri | 74 |
ref_data.groupby(['Species', 'Season']).agg({'d13c': 'count'})| d13c | ||
|---|---|---|
| Species | Season | |
| H.dipterurus | Cold | 18 |
| Warm | 63 | |
| N.entemedor | Cold | 15 |
| Warm | 54 | |
| R.steindachneri | Cold | 3 |
| Warm | 71 |
ref_data.groupby(['Species', 'Sex']).agg({'d13c': 'count'})| d13c | ||
|---|---|---|
| Species | Sex | |
| H.dipterurus | Female | 44 |
| Male | 37 | |
| N.entemedor | Female | 55 |
| Male | 14 | |
| R.steindachneri | Female | 31 |
| Male | 43 |
ref_data.groupby(['Species', 'Maturity']).agg({'d13c': 'count'})| d13c | ||
|---|---|---|
| Species | Maturity | |
| H.dipterurus | Adult | 36 |
| Juvenile | 45 | |
| N.entemedor | Adult | 55 |
| Juvenile | 14 | |
| R.steindachneri | Adult | 26 |
| Juvenile | 48 |
And for every possible combination:
ref_data.groupby(['Species', 'Season', 'Sex', 'Maturity']).agg({'d13c':'count'})| d13c | ||||
|---|---|---|---|---|
| Species | Season | Sex | Maturity | |
| H.dipterurus | Cold | Female | Adult | 3 |
| Juvenile | 9 | |||
| Male | Adult | 2 | ||
| Juvenile | 4 | |||
| Warm | Female | Adult | 9 | |
| Juvenile | 23 | |||
| Male | Adult | 22 | ||
| Juvenile | 9 | |||
| N.entemedor | Cold | Female | Adult | 13 |
| Juvenile | 2 | |||
| Warm | Female | Adult | 30 | |
| Juvenile | 10 | |||
| Male | Adult | 12 | ||
| Juvenile | 2 | |||
| R.steindachneri | Cold | Female | Juvenile | 1 |
| Male | Adult | 1 | ||
| Juvenile | 1 | |||
| Warm | Female | Adult | 5 | |
| Juvenile | 25 | |||
| Male | Adult | 20 | ||
| Juvenile | 21 |
# Species
n_sp = len(glm_data.Species.unique())
sp_names = glm_data['Species'].unique()
glm_data['Species'] = pd.Categorical(glm_data['Species']).codes
sp_idx = glm_data.Species.values2.3 Justification of methods
Frequentist null hypothesis testing has been useful in ecological studies; however, it has been suggested that inferences should, instead, be made from models, likelihodd ratios or in probabilistic terms (i.e. Bayesian Inference (Ellison 2004, Hobbs & Hilborn 2006, Gerrodette 2011, Armhein et al. 2019)); hence, analyses were based on Bayesian Inference. In general, Bayesian Inference consists on the reallocation of credibility among a space of candidate possibilities, using the Bayes’ Theorem to evaluate the credibility of a parameter given the data and prior knowledge of the parameter (Bolstad 2004, Kruschke 2015). Details on the implementation of the models and the sampling of the posterior distributions are given in each section; however, each model was run until convergence; i.e., 0 divergences during the posterior sampling and Gelman-Rubick statistics equal to 1.0 for every parameter. Other graphical diagnostics such as Posterior Predictive Checks and energy plots (Betancourt 2017, Gabry et al. 2017) are also presented. Every sample after convergence (posterior) was kept. This approach was taken since thinning the posterior sample is unadvised, unless there are computational restrictions, due to a reduction in the precision of the estimates (Link & Eaton 2012, Team 2022). Still, the number of posterior samples for each model was dependent on the number of independent samples (effective sample sizes, ess) being over 2000, both for bulk and tail ess (affecting the reliability of the median and highest density intervals, respectively, Martin 2018).
2.4 Comparisons of means and effects of predictors
The isotopic spaces of the three species were described using a custom hierarchichal bivariate model, in which the effects of the climatic seasons (warm vs. cold), sexes and age categories (juveniles vs. adults) on the isotopic values are nested within each species, meaning that the isotopic space of each species is the result of two linear models (one per isotopic ratio) of the covariates. This model was implemented using the pymc3 library (v. 3.11.2, Salvatier et al. 2016) in Python 3 (v. 3.8.2, Van Rossum & Drake 2009), with three chains that were tuned for 25,000 iterations and a posterior sample of 2,000 iterations (draws). The model was specified as follows, where \(j\) represents the isotopic ratio, \(i\) the species, \(a\) the intercept (i.e. the mean isotopic value) and \(b\) the slopes of the regression (i.e. the difference between both levels of the covariates):
- Hyper-priors
- \(\nu \sim Exponential(\lambda = 1/29)+1\): global degrees-of-freedom (d.f.). The shifted exponential distribution spreads the credibility both for nearly normal and heavy-tailed distributions (Kruschke 2012).
- \(\mu_j \sim StudentT(\mu = mean(data_j), \sigma = sd(data_j)*1000, \nu\)): Global mean of each isotope, centered on the mean of the pooled data for each isotope and a standard deviation 1000 times that of the pooled data, with the previously described d.f.
- \(\sigma_{j,a} \sim HalfCauchy(\beta = 10)\): global standard deviation of the intercepts, following a non-commital Half-Cauchy distribution.
- \(\sigma_{j,b} \sim HalfCauchy(\beta = 10)\): global standard deviation of the slopes, with the same distribution as that of the intercepts.
- \(\mu_{j,b} \sim StudentT(\mu = 0, \sigma = 10, \nu)\): global mean of the slopes, following a non-commital Student-T distribution with the previouslu described d.f.
- Parameter priors
- \(\nu_i \sim Exponential(\lambda = 1/29) + 1\): Degrees-of-Freedom for each species, with the same specification that the global d.f.
- \(Sigma_i \sim LKJCholesky(n = 2, \eta = 1, \sigma = HalfCauchy(\beta = 10))\): Covariance matrix for both isotopes for each species, following a Cholesky-decomposed LKJ prior with equi-probability for every matrix, and each standard deviation following a non-commital Half-Cauchy distribution. Used instead of the Wishart distribution due to its higher efficiency to compute when paired with a Cholesky decomposition (Lewandowski et al. 2009).
- \(\mu_{j,i} \sim StudentT(\mu = \mu_j, \sigma_{j,a}, \nu_i)\): Intercepts of the linear model for each species and isotopic ratio; i.e., the mean of each isotopic ration with a standard daviation \(\sigma_{j,a}\) and d.f. \(nu_i\).
- \(\beta_{j,b,i} \sim Laplace(\mu_{j,b,i}, b = \sigma_{j,i})\): Represents the slope for each isotope and species, following a Laplace distribution, which results in a L1 regularization (i.e. a “Bayesian Lasso” (Park & Casella 2012)), with parameters:
- \(\mu_{j,b,i} \sim StudentT(\mu_{j,b}, \sigma_{j,b}, \nu_i)\): distribution of means of the intercept for each isotopic ratio, following a Student T distribution with mean 0, standard deviation 10 and d.f. \(\nu_i\).
- \(\sigma_{n,j,i} \sim HalfCauchy(\beta = 10)\): scale of the Laplace distribution, following a non-commital Half-Caucy distribution.
- Likelihood model
- \(Y_i \sim MvStudentT(\mu = [y_{1,i}, y_{2,i}], \Sigma_i, \nu)\): The bivariate distribution of the isotopic values following a Multivariate Student T distribution, with covariance matrix \(\Sigma_i\), d.f. \(\nu\) and means under the linear model:
- \(y_{j,i} = \mu_{j,i} + \beta_{1,j,i}*Sex + \beta_{2,j,i}*Season + \beta_{3,j,i}*Age\)
- \(Y_i \sim MvStudentT(\mu = [y_{1,i}, y_{2,i}], \Sigma_i, \nu)\): The bivariate distribution of the isotopic values following a Multivariate Student T distribution, with covariance matrix \(\Sigma_i\), d.f. \(\nu\) and means under the linear model:
This parametrization obeyed the following reasons: i) a bivariate model allows accounting for the covariation between bulk isotopic values, which is relevant since these depend both on the isotopic baseline and the trophic level; hence, having a joint distribution that is not orthogonal; and, ii) the distributions used have heavier tails than a normal distribution, which assigns a higher probability to extreme values and, thus, allows to make robust estimations of the parameters (Kruschke 2012).
Important
There are some cases of class imbalance and small sample sizes. Hierarchical Bayesian models aid in propagating the uncertainty and make every sample “contribute” to every estimate (including those of other groups) due to the partial pooling of the data and the effect of shrinkage, minimizing the effect of small sample sizes. This effect is further minimized by the robust inference allowed by the Student t likelihood. Moreover, SIA integrates information over a time window, “reducing” (to some extent) the sample size needed to make inferences (Jackson et al. 2011). Nevertheless, neither Bayesian inference nor SIA can make information out of thin air, and the results for those groups should be carefuly interpreted.
with pm.Model() as full_model:
obs = glm_data[['d13c', 'd15n']].values
#----Hyper-priors----
## Degrees of freedom.
# Shifted exponential to spread the credibility among heavy-tailed
# (small d.f.) and light-tailed (d.f) distributions (normal-like)
nu = pm.Exponential('ν', lam = 1/29) + 1
## Mean Isotopic values ~ StudentT (Gaussian-like, heavier tails than a normal dist.)
# Centered on the global mean of each isotope to keep the distribution scaled
# Standard deviation: 1000 times the standard deviation of the pooled data
# D.F.: Previously defined
µ1 = pm.StudentT('δ13C', mu = glm_data.d13c.mean(),
sd = glm_data.d13c.std()*1000,
nu = nu)
µ2 = pm.StudentT('δ15N', mu = glm_data.d15n.mean(),
sd = glm_data.d15n.std()*1000,
nu = nu)
## Parameters
# Standard deviation of the intercepts. Non-commital Half-Cauchy.
sigma_a = pm.HalfCauchy('sd_a', beta = 10)
# Standard deviation of the slopes. Non-commital Half-Cauchy.
sigma_b = pm.HalfCauchy('sd_b', beta = 10)
# D.F. of the Distribution. Same parametrization as before.
nu2 = pm.Exponential('nu_a', lam = 1/29) + 1
# Distribution of means of the slopes. Non-commital Student-T distribution.
mu_b = pm.StudentT('mu_b', mu = 0, sd = 10, nu = nu)
#----Priors on the parameters----
## Means: Student-T
mu1 = pm.StudentT('µδ13C',
mu = µ1,
sigma = pm.HalfCauchy('sδ13C', beta = 10),
nu = nu2,
shape = n_sp)
mu2 = pm.StudentT('µδ15N',
mu = µ2,
sigma = pm.HalfCauchy('sδ15N', beta = 10),
nu = nu2,
shape = n_sp)
## Intercepts: Student-T distribution centered on global mean isotopic values
a1 = pm.StudentT('⍺δ13C', mu = µ1, sigma = sigma_a, nu = nu2, shape = n_sp)
a2 = pm.StudentT('⍺δ15N', mu = µ2, sigma = sigma_a, nu = nu2, shape = n_sp)
## Slopes: Student T distribution
## Slopes: Laplace distribution.
# Equivalent to a Lasso regression; i.e., L1 regularization.
# Affects the sum of absolutes of the residuals. The effect is that small effects -> 0.
# Especially useful when considering the measuring error of the mass spectrometer.
# Main effects:
# Sex:
T_b1c = pm.Laplace('Sex_δ13C', mu = mu_b, b = sigma_b, shape = n_sp)
T_b1n = pm.Laplace('Sex_δ15N', mu = mu_b, b = sigma_b, shape = n_sp)
# Season:
T_b2c = pm.Laplace('Season_δ13C', mu = mu_b, b = sigma_b, shape = n_sp)
T_b2n = pm.Laplace('Season_δ15N', mu = mu_b, b = sigma_b, shape = n_sp)
# Maturity stages:
T_b3c = pm.Laplace('Maturity_δ13C', mu = mu_b, b = sigma_b, shape = n_sp)
T_b3n = pm.Laplace('Maturity_δ15N', mu = mu_b, b = sigma_b, shape = n_sp)
## Covariance Matrix
# LKJ prior with eta = 1, meaning a uniform distribution of the whole matrix
# Prior of every sd: Non-commital Half-Cauchy
pL = pm.LKJCholeskyCov('pL', n = 2, eta = 1,
sd_dist = pm.HalfCauchy.dist(beta = 10), shape = n_sp)
# The LKJ distribution is decomposed by a Cholesky factor, so we decompose it:
L = pm.expand_packed_triangular(2, pL)
Σ = pm.Deterministic('Σ', L.dot(L.T))
#----Algebraic expression of the model----
# Each isotope is a linear model with the effect of the covariates
d13c = a1[sp_idx] +\
T_b1c[sp_idx]*glm_data.Sex.values +\
T_b2c[sp_idx]*glm_data.Season.values +\
T_b3c[sp_idx]*glm_data.Maturity.values
d15n = a2[sp_idx] +\
T_b1n[sp_idx]*glm_data.Sex.values +\
T_b2n[sp_idx]*glm_data.Season.values +\
T_b3n[sp_idx]*glm_data.Maturity.values
# Bivariate tensor for the Likelihood model:
glm = tt.stack([d13c, d15n]).T
mus = tt.stack([mu1[sp_idx], mu2[sp_idx]]).T
#----Likelihood model----
# In this step the hierarchical estimates are included;
# hence, it includes their uncertainty.
y = pm.MvStudentT('mvT_sp',
mu = glm,# Linear model of each isotopes
cov = Σ, # Covariance Matrix
nu = nu, # Degrees of freedom
observed = obs) # Observed data
means = pm.MvStudentT('µ_sp',
mu = mus,
cov = Σ,
nu = nu,
observed = obs)Graph of the hierarchical model.
pm.model_to_graphviz(full_model)
# Parameters of the NUTS.
tune = 25000
draws = 5000
# Variational Inference to start the sampling process
init = 'advi+adapt_diag'Sampling of the posterior:
with full_model:
#----Sampling----
full_trace = pm.sample(draws = draws, # Posterior samples to keep
tune = tune, # Burn-in iterations
chains = 3, # Number of chains
cores = 3, # Number of chains run in parallel
init = init, # Initiation method,
return_inferencedata = False, # NOT return an arviz.InferenceData
random_seed = 0, # For consistency
progressbar = False) # NOT show a progress barAuto-assigning NUTS sampler...
Initializing NUTS using advi+adapt_diag...
Convergence achieved at 19700
Interrupted at 19,699 [9%]: Average Loss = 1,722.9
Multiprocess sampling (3 chains in 3 jobs)
NUTS: [pL, Maturity_δ15N, Maturity_δ13C, Season_δ15N, Season_δ13C, Sex_δ15N, Sex_δ13C, ⍺δ15N, ⍺δ13C, µδ15N, sδ15N, µδ13C, sδ13C, mu_b, nu_a, sd_b, sd_a, δ15N, δ13C, ν]
Sampling 3 chains for 25_000 tune and 5_000 draw iterations (75_000 + 15_000 draws total) took 1038 seconds.2.4.1 Diagnostics
full_mod = az.from_pymc3(trace = full_trace, model = full_model)# Save model
#with open(output_dir+'/model/az_model', 'wb') as model_file:
# pickle.dump(full_mod, model_file)
# Save trace
#with open(output_dir+'/model/pm_trace', 'wb') as model_file:
# pickle.dump(full_trace, model_file)# Load model for consistency
#with open(output_dir+'/model/az_model', 'rb') as model_file:
# full_mod = pickle.load(model_file)
#with open(output_dir+'/model/az_model', 'rb') as model_file:
# full_trace = pickle.load(model_file)Summary statistics of the posterior distributions of the parameters. Gelman-Statistic values equal to 1.0 (< 1.01) and Effective Sample Sizes (both Bulk and Tail) over 2000 for every parameter.
az.summary(full_mod, hdi_prob = 0.95)| mean | sd | hdi_2.5% | hdi_97.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| δ13C | -13.995 | 0.904 | -15.885 | -12.218 | 0.009 | 0.006 | 12202.0 | 8109.0 | 1.0 |
| δ15N | 16.508 | 0.764 | 14.956 | 17.988 | 0.008 | 0.005 | 11778.0 | 7825.0 | 1.0 |
| mu_b | -0.111 | 0.145 | -0.405 | 0.172 | 0.001 | 0.001 | 14501.0 | 9645.0 | 1.0 |
| µδ13C[0] | -13.997 | 0.191 | -14.370 | -13.624 | 0.002 | 0.001 | 12398.0 | 11332.0 | 1.0 |
| µδ13C[1] | -12.385 | 0.129 | -12.630 | -12.125 | 0.001 | 0.001 | 15640.0 | 11048.0 | 1.0 |
| µδ13C[2] | -16.119 | 0.109 | -16.338 | -15.910 | 0.001 | 0.001 | 13528.0 | 11247.0 | 1.0 |
| µδ15N[0] | 16.161 | 0.149 | 15.869 | 16.452 | 0.001 | 0.001 | 12816.0 | 11541.0 | 1.0 |
| µδ15N[1] | 18.058 | 0.099 | 17.870 | 18.255 | 0.001 | 0.001 | 14475.0 | 11300.0 | 1.0 |
| µδ15N[2] | 16.179 | 0.087 | 16.006 | 16.344 | 0.001 | 0.001 | 12963.0 | 11430.0 | 1.0 |
| ⍺δ13C[0] | -14.028 | 0.480 | -14.927 | -13.065 | 0.006 | 0.004 | 7143.0 | 9346.0 | 1.0 |
| ⍺δ13C[1] | -12.158 | 0.227 | -12.608 | -11.715 | 0.002 | 0.002 | 9716.0 | 9840.0 | 1.0 |
| ⍺δ13C[2] | -15.529 | 0.483 | -16.436 | -14.538 | 0.006 | 0.004 | 6458.0 | 7192.0 | 1.0 |
| ⍺δ15N[0] | 15.231 | 0.359 | 14.513 | 15.925 | 0.004 | 0.003 | 6816.0 | 9450.0 | 1.0 |
| ⍺δ15N[1] | 17.788 | 0.200 | 17.400 | 18.180 | 0.002 | 0.002 | 8775.0 | 9503.0 | 1.0 |
| ⍺δ15N[2] | 15.752 | 0.534 | 14.645 | 16.676 | 0.007 | 0.005 | 6350.0 | 8275.0 | 1.0 |
| Sex_δ13C[0] | -0.302 | 0.272 | -0.855 | 0.219 | 0.002 | 0.002 | 13199.0 | 10522.0 | 1.0 |
| Sex_δ13C[1] | -0.134 | 0.272 | -0.694 | 0.395 | 0.002 | 0.002 | 15605.0 | 10292.0 | 1.0 |
| Sex_δ13C[2] | 0.060 | 0.196 | -0.315 | 0.456 | 0.002 | 0.001 | 14920.0 | 11701.0 | 1.0 |
| Sex_δ15N[0] | -0.082 | 0.207 | -0.472 | 0.341 | 0.002 | 0.001 | 11893.0 | 10560.0 | 1.0 |
| Sex_δ15N[1] | -0.190 | 0.220 | -0.635 | 0.238 | 0.002 | 0.002 | 15431.0 | 10737.0 | 1.0 |
| Sex_δ15N[2] | -0.024 | 0.157 | -0.333 | 0.286 | 0.001 | 0.001 | 16323.0 | 11103.0 | 1.0 |
| Season_δ13C[0] | -0.728 | 0.371 | -1.434 | -0.017 | 0.004 | 0.003 | 9062.0 | 10988.0 | 1.0 |
| Season_δ13C[1] | -0.203 | 0.254 | -0.725 | 0.275 | 0.003 | 0.002 | 9764.0 | 9525.0 | 1.0 |
| Season_δ13C[2] | -0.304 | 0.435 | -1.218 | 0.529 | 0.005 | 0.004 | 7016.0 | 7164.0 | 1.0 |
| Season_δ15N[0] | 1.784 | 0.297 | 1.206 | 2.366 | 0.003 | 0.002 | 9305.0 | 10307.0 | 1.0 |
| Season_δ15N[1] | 0.458 | 0.229 | 0.022 | 0.922 | 0.002 | 0.002 | 8542.0 | 8725.0 | 1.0 |
| Season_δ15N[2] | 0.414 | 0.506 | -0.441 | 1.468 | 0.006 | 0.005 | 6719.0 | 8149.0 | 1.0 |
| Maturity_δ13C[0] | 1.157 | 0.398 | 0.378 | 1.934 | 0.004 | 0.003 | 8695.0 | 10915.0 | 1.0 |
| Maturity_δ13C[1] | -0.245 | 0.294 | -0.841 | 0.329 | 0.003 | 0.002 | 13819.0 | 10579.0 | 1.0 |
| Maturity_δ13C[2] | -0.463 | 0.218 | -0.898 | -0.053 | 0.002 | 0.001 | 13527.0 | 11509.0 | 1.0 |
| Maturity_δ15N[0] | -0.897 | 0.279 | -1.445 | -0.350 | 0.003 | 0.002 | 8263.0 | 11065.0 | 1.0 |
| Maturity_δ15N[1] | -0.389 | 0.238 | -0.866 | 0.064 | 0.002 | 0.002 | 15017.0 | 10699.0 | 1.0 |
| Maturity_δ15N[2] | 0.022 | 0.170 | -0.298 | 0.376 | 0.001 | 0.001 | 13985.0 | 11095.0 | 1.0 |
| ν | 1.559 | 0.340 | 0.924 | 2.229 | 0.003 | 0.002 | 9236.0 | 8727.0 | 1.0 |
| sd_a | 1.892 | 0.877 | 0.681 | 3.529 | 0.009 | 0.007 | 14428.0 | 9423.0 | 1.0 |
| sd_b | 0.546 | 0.168 | 0.274 | 0.884 | 0.002 | 0.001 | 8818.0 | 9953.0 | 1.0 |
| nu_a | 32.802 | 30.069 | 0.097 | 93.053 | 0.223 | 0.178 | 14556.0 | 8534.0 | 1.0 |
| sδ13C | 2.936 | 2.130 | 0.644 | 6.783 | 0.023 | 0.016 | 14702.0 | 8659.0 | 1.0 |
| sδ15N | 2.060 | 1.847 | 0.303 | 5.230 | 0.021 | 0.015 | 11879.0 | 7494.0 | 1.0 |
| pL[0] | 0.944 | 0.059 | 0.833 | 1.064 | 0.001 | 0.000 | 8645.0 | 9254.0 | 1.0 |
| pL[1] | -0.471 | 0.044 | -0.554 | -0.381 | 0.000 | 0.000 | 11209.0 | 11333.0 | 1.0 |
| pL[2] | 0.560 | 0.035 | 0.492 | 0.628 | 0.000 | 0.000 | 9231.0 | 9005.0 | 1.0 |
| Σ[0,0] | 0.895 | 0.112 | 0.680 | 1.117 | 0.001 | 0.001 | 8645.0 | 9254.0 | 1.0 |
| Σ[0,1] | -0.446 | 0.064 | -0.573 | -0.324 | 0.001 | 0.000 | 9200.0 | 9280.0 | 1.0 |
| Σ[1,0] | -0.446 | 0.064 | -0.573 | -0.324 | 0.001 | 0.000 | 9200.0 | 9280.0 | 1.0 |
| Σ[1,1] | 0.538 | 0.068 | 0.405 | 0.670 | 0.001 | 0.001 | 7994.0 | 8217.0 | 1.0 |
pps = pm.sample_posterior_predictive(trace = full_trace,
model = full_model,
progressbar = False,
random_seed = 0)
posteriors = az.from_pymc3(posterior_predictive = pps,
model = full_model)# Save posterior predictive samples
#with open(output_dir+'/model/posteriors_mvt', 'wb') as post_mvt_file:
# pickle.dump(posteriors, post_mvt_file)# Load posterior predictive samples
#with open(output_dir+'/model/posteriors_mvt', 'rb') as post_mvt_file:
# posteriors = pickle.load(post_mvt_file)Posterior Predictive Checks for the likelihood model. The observed distribution (black) is between the posterior predictive samples (blue). Each posterior predictive sample consists on a set with the same number of observations as the original data, generated based on a parameter from the posterior samples.
az.plot_ppc(posteriors, mean = False, kind = 'cumulative', num_pp_samples = 500);
az.plot_ppc(posteriors, kind = 'scatter', mean = False);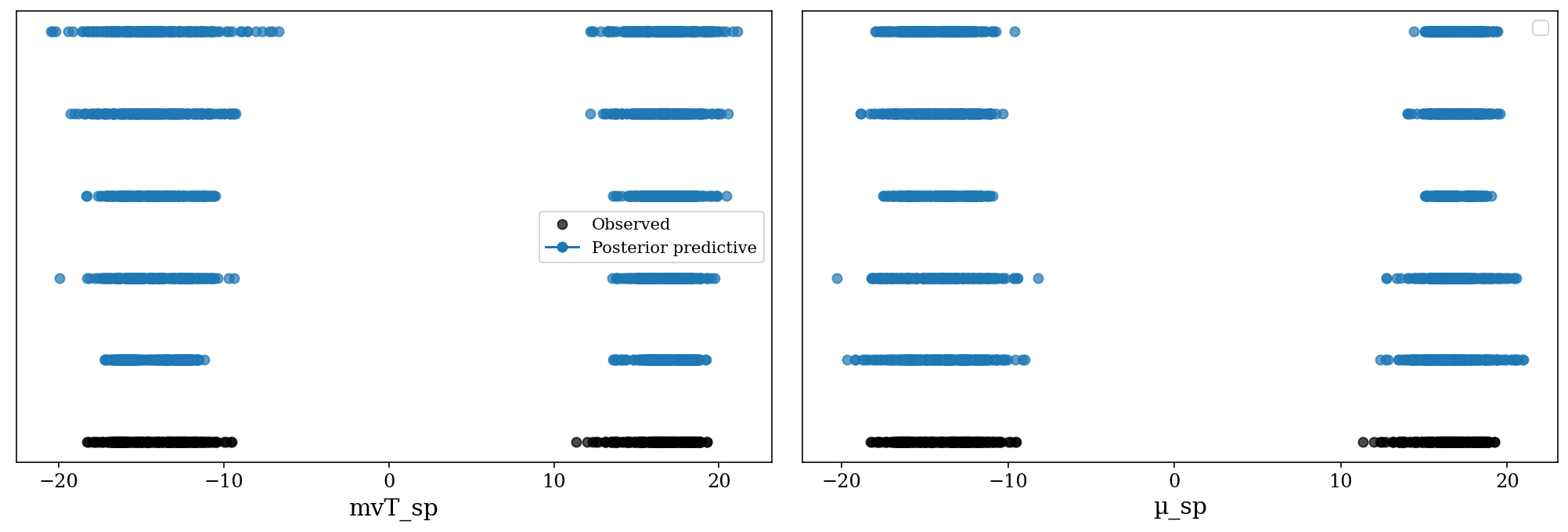
Energy plot and Bayesian Fraction of Missing Information (BFMI). The energy plot shows similar densities between the marginal and transition energies from the Hamiltonian simulation, meaning that the sampler was not stuck in a particular area of the posterior distribution, which is validated through the BFMI values (Betancourt 2017).
az.plot_energy(full_mod, fill_color = ('C0', 'C3'));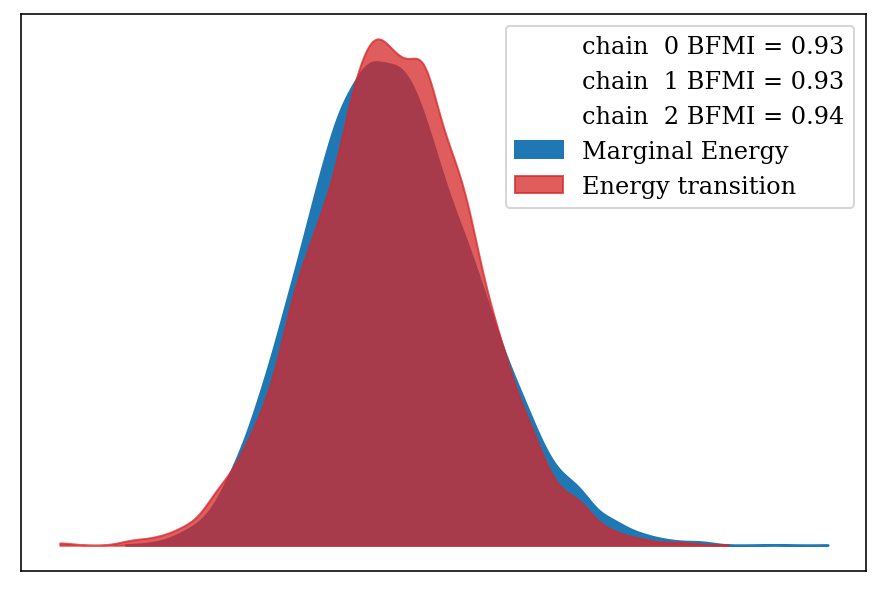
2.4.1.1 Effective sample sizes, autocorrelations and no-thinning.
The autocorrelation (i.e., the correlation between the sample\(_i\) and the sample\(_{i-1}\)) directly affects the effective sample size (ess) estimation (higher autocorrelations, lower ess). For this reason, a very common practice is to thin the posterior sample (i.e. keep only 1 out of every k-th iteration after convergence); however, this is unadvised since it leads to a reduction in the precision of the estimates(Link & Eaton 2012), making it feasible only to reduce computational requirements (Team 2022). Moreover, one of the advantages of using NUTS is that the samples can be uncorrelated, since the new state of the chain depends more on the probability “surface” rather than the previous position of the particle. Shown in the following autocorrelation plot:
rc = {'plot.max_subplots': 120}
az.rcParams.update(rc)
az.plot_autocorr(full_mod, combined = True);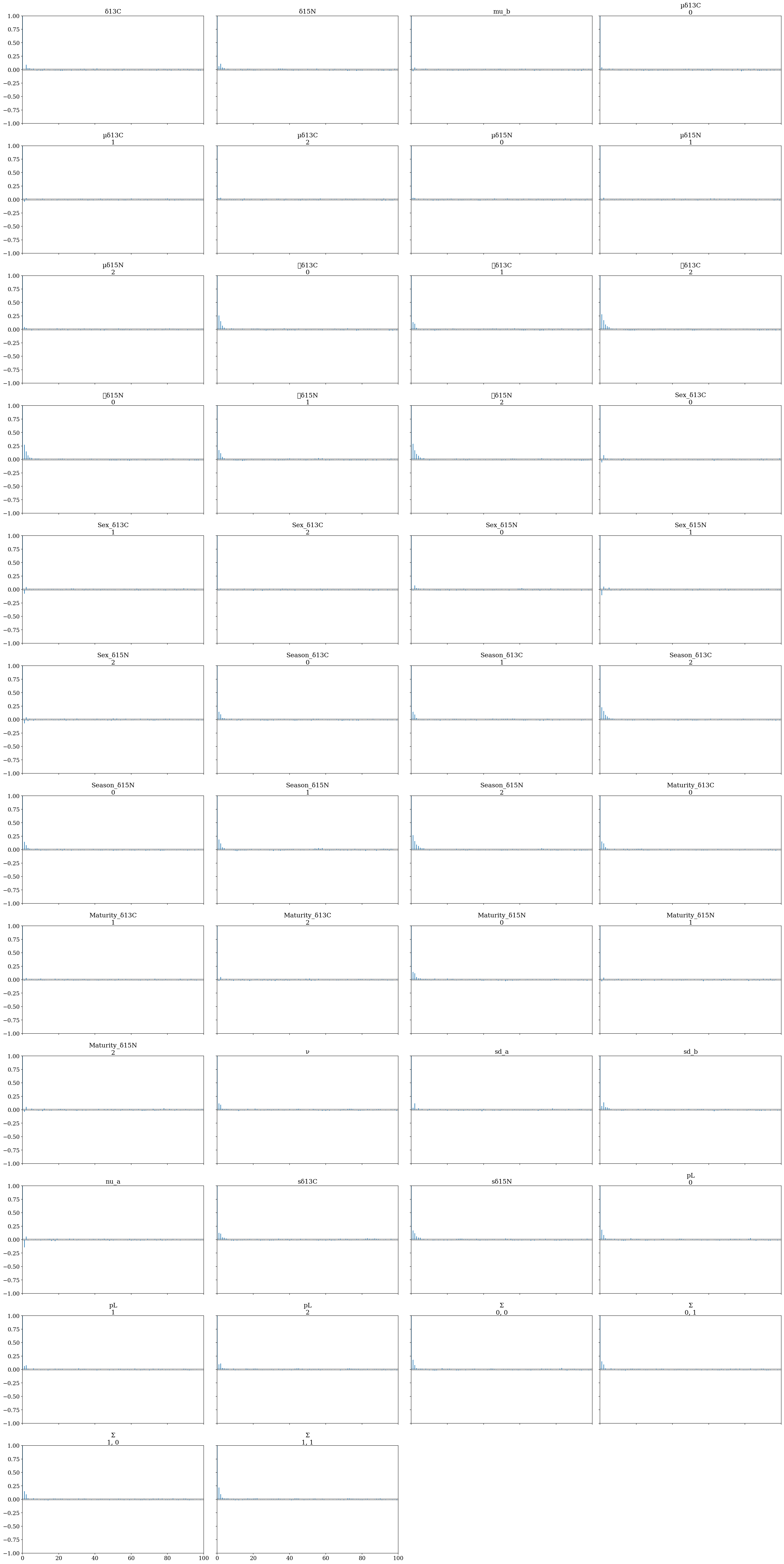
Parallel coordinates plots for each parameter of interest within the model. Shows that every sample of the posterior distribution was non-divergent. A) Mean values for each species and B) Slopes for each covariate for each species; where: 0: H. dipterurus, 1: N. entemedor, 2: R. steindachneri
az.plot_parallel(full_mod, var_names=['µ'], filter_vars='like');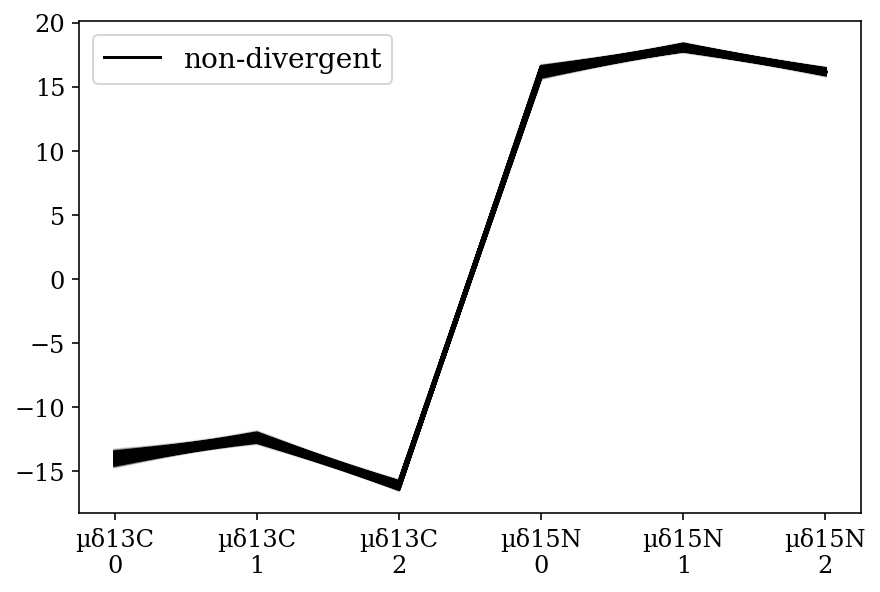
ax = az.plot_parallel(full_mod, var_names = ['Season', 'Sex', 'Maturity'], filter_vars = 'like');
ax.set_xticklabels(ax.get_xticklabels(), rotation=70);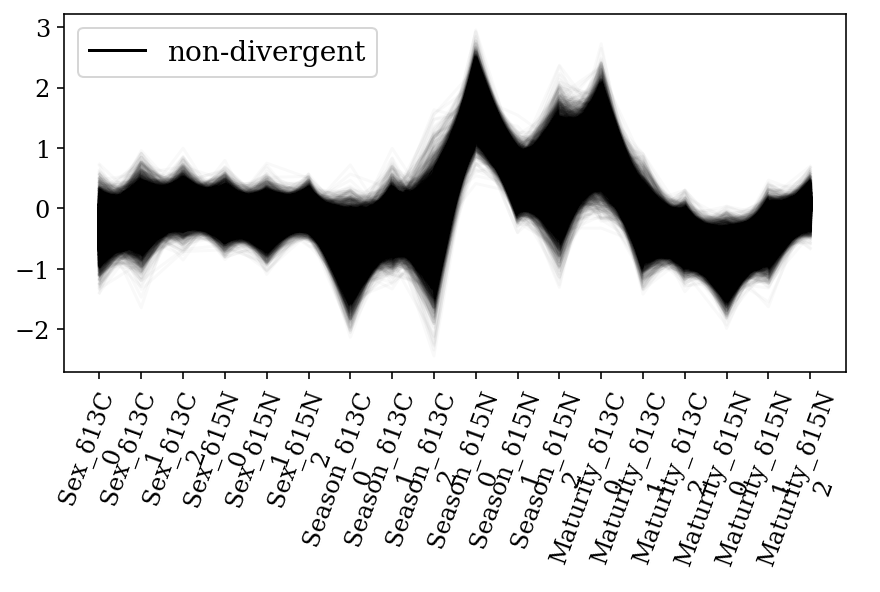
2.5 A note on the interpretation of results
It is important to understand the interpretation of the slope of a categorical covariate before going to the description of the results. Consider a univariate model with a binary covariate (\(X\)) such as the ones of this model:
\(Y = \beta_0 + \beta_1*X + \epsilon\)
\(\therefore\)
If \(X = 0\): \(Y_0 = \beta_0 + \beta_1*0 + \epsilon \implies Y_0 = \beta_0 + \epsilon\)
If \(X = 1\): \(Y_0 = \beta_0 + \beta_1*1 + \epsilon \implies Y_1 = \beta_0 + \beta_1 + \epsilon\)
I.e., the slope represents the difference between the means of both classes. This is demonstrabe if we substract both equations (\(\Delta_Y\)):
\(Y = \beta_0 + \beta_1 + \epsilon = \beta_0 + \epsilon \implies \Delta_Y = \beta_0 - \beta_0 + \beta_1 + \epsilon - \epsilon \therefore \Delta_Y = \beta_1\)
Taking this into account, the slopes in this work represent the difference (in ‰) between the two classes being analysed.
2.6 Results
2.6.1 Dummy variables
Labels for groups are assigned alphabetically, starting at 0 (Python’s indices start at 0): - Species: - H. dipterurus: 0 - N. entemedor: 1 - R. steindachneri: 2 - Season: - Cold: 0 - Warm: 1 - Sex: - Female: 0 - Male: 1 - Maturity: - Adult: 0 - Juvenile: 1
ref_data['Species_codes'] = pd.Categorical(ref_data['Species']).codes
ref_data['Season_codes'] = pd.Categorical(ref_data['Season']).codes
ref_data['Sex_codes'] = pd.Categorical(ref_data['Sex']).codes
ref_data['Maturity_codes'] = pd.Categorical(ref_data['Maturity']).codes
ref_data.drop(columns = ['d15n', 'd13c'])| Species | Year | Season | Sex | Maturity | Species_codes | Season_codes | Sex_codes | Maturity_codes | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | H.dipterurus | 2015 | Warm | Male | Juvenile | 0 | 1 | 1 | 1 |
| 1 | H.dipterurus | 2015 | Warm | Female | Juvenile | 0 | 1 | 0 | 1 |
| 2 | H.dipterurus | 2015 | Warm | Male | Adult | 0 | 1 | 1 | 0 |
| 3 | H.dipterurus | 2015 | Warm | Female | Juvenile | 0 | 1 | 0 | 1 |
| 4 | H.dipterurus | 2015 | Warm | Male | Adult | 0 | 1 | 1 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 219 | R.steindachneri | 2016 | Warm | Male | Juvenile | 2 | 1 | 1 | 1 |
| 220 | R.steindachneri | 2016 | Warm | Male | Adult | 2 | 1 | 1 | 0 |
| 221 | R.steindachneri | 2016 | Warm | Male | Adult | 2 | 1 | 1 | 0 |
| 222 | R.steindachneri | 2016 | Warm | Male | Adult | 2 | 1 | 1 | 0 |
| 223 | R.steindachneri | 2016 | Warm | Female | Adult | 2 | 1 | 0 | 0 |
224 rows × 9 columns
2.6.2 Isotopic means
The blue trace corresponds to H. dipterurus, the yellow to N. entemedor and the green to R. steindachneri.
\(\mu\): Posterior distribution of the means of each species for each isotope. They are among the higher levels on the hierarchy, hence including the uncertainty in the other estimates:
\(\mu_{\delta^{13}C}\): Shows the separation between species in \(\delta^{13}C\). N. entemedor shows intermediate values among the other two species.
\(\mu_{\delta^{15}N}\): Ídem.
az.plot_trace(full_mod, var_names = 'µδ', filter_vars = 'like');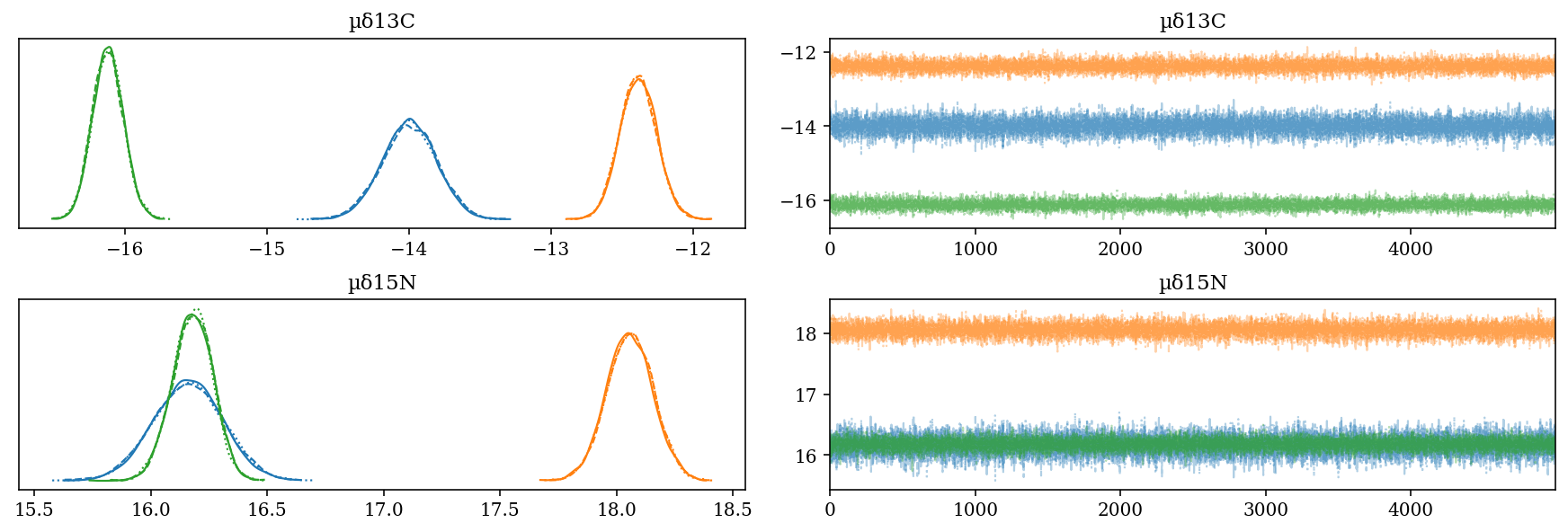
2.6.3 Effect of the sex
- \(Sex\_\): Slope for the sexes of each species for each isotope.
- Codes: Female = 0, Male = 1
- The difference between sexes is small (\(\approx 0\)‰).
az.plot_trace(full_mod, var_names = 'Sex', filter_vars = 'like');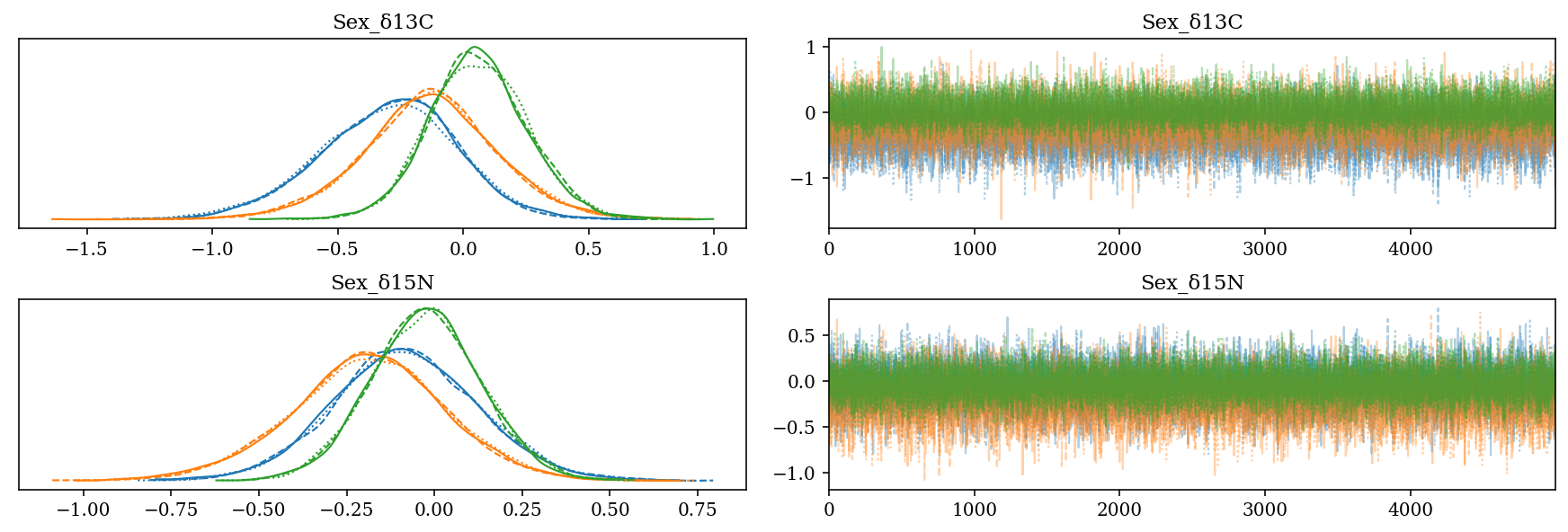
2.6.4 Effect of the season
- \(Season\_\): Slope for the season:
- Codes: Cold = 0, Warm = 1
- H. dipterurus: Difference between seasons of \(\approx 1\)‰ in \(\delta^{13}C\) and \(\approx 2\)‰ in \(\delta^{15}N\).
- N. entemedor: \(\Delta^{15}N \in (-1,0)\)‰
- The posterior distributions of R. steindachneri are very broad, possibly due to the limited sample size of three for the cold season.
az.plot_trace(full_mod, var_names = 'Season', filter_vars = 'like');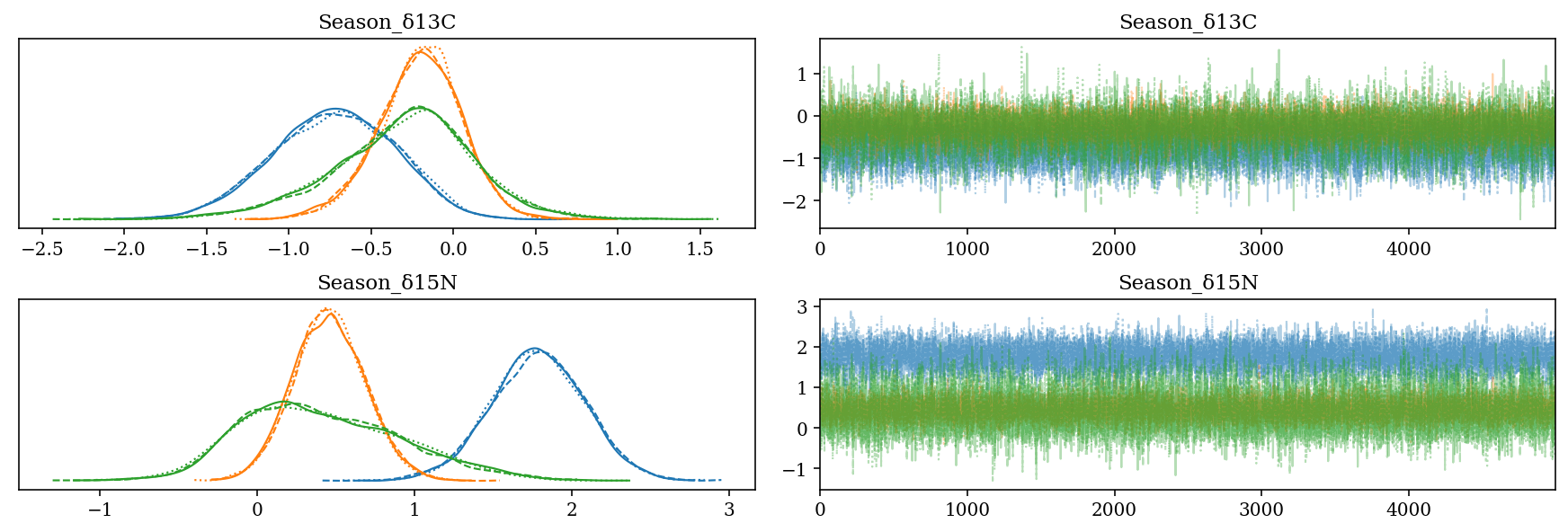
2.6.5 Effect of the maturity stage
- \(Maturity\_\): Slope value for the age category of each isotope for each species:
- Codes: Adult = 0, Juvenile = 1
- H. dipterurus \(\Delta^{13}C \in (0,2)\), \(\Delta^{15}N \in (-1.5,0]\)
- N. entemedor \(\Delta^{15}N \in [-1.5,0)\)
- R. steindachneri: \(\Delta^{13}C \in (-1,0)\)
az.plot_trace(full_mod, var_names = 'Maturity', filter_vars = 'like');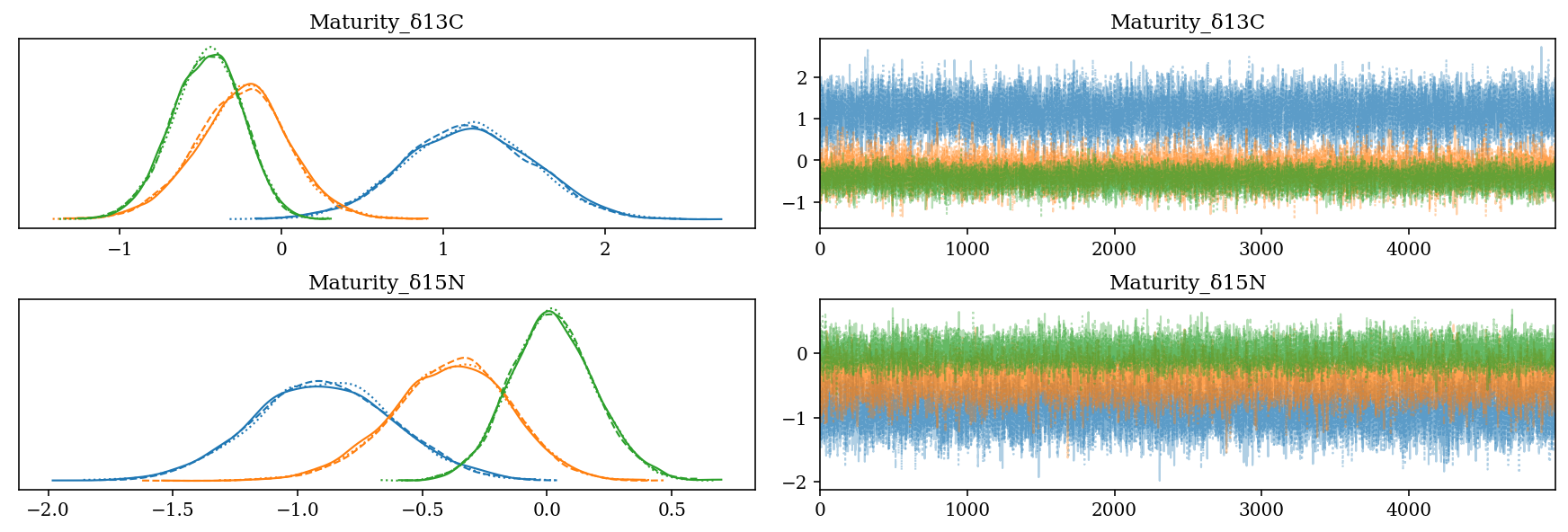
2.6.6 Inference
The results are summarized and further interpreted below, evaluating the \(P(\beta \neq 0)\), based on that if \(P(\beta < 0)\) or \(P(\beta > 0) \approx 50\%\) the \(P(\beta \neq 0)\) is very low (\(\sim 50\%\) of the distribution on either side of 0).
2.6.6.1 Sexes
In general, the effect is small, with probabilities smaller than 75% in most cases. The only exception was in \(\delta^{13}C\) for H. dipterurus with \(P(\beta < 0) \approx 90\%\), suggesting that females possibly had more coastal habits than males (\(\bar{\beta} = -0.32\)‰).
- Interpretation:
- \(\delta^{13}C_f = \delta^{13}C + \beta*0 = \delta^{13}C\)
- \(\delta^{13}C_m = \delta^{13}C + \beta*1 = \delta^{13}C - 0.32\)‰; i.e., males had more negative values.
az.plot_posterior(full_mod, var_names = 'Sex', filter_vars = 'like', ref_val = 0, hdi_prob = 0.95);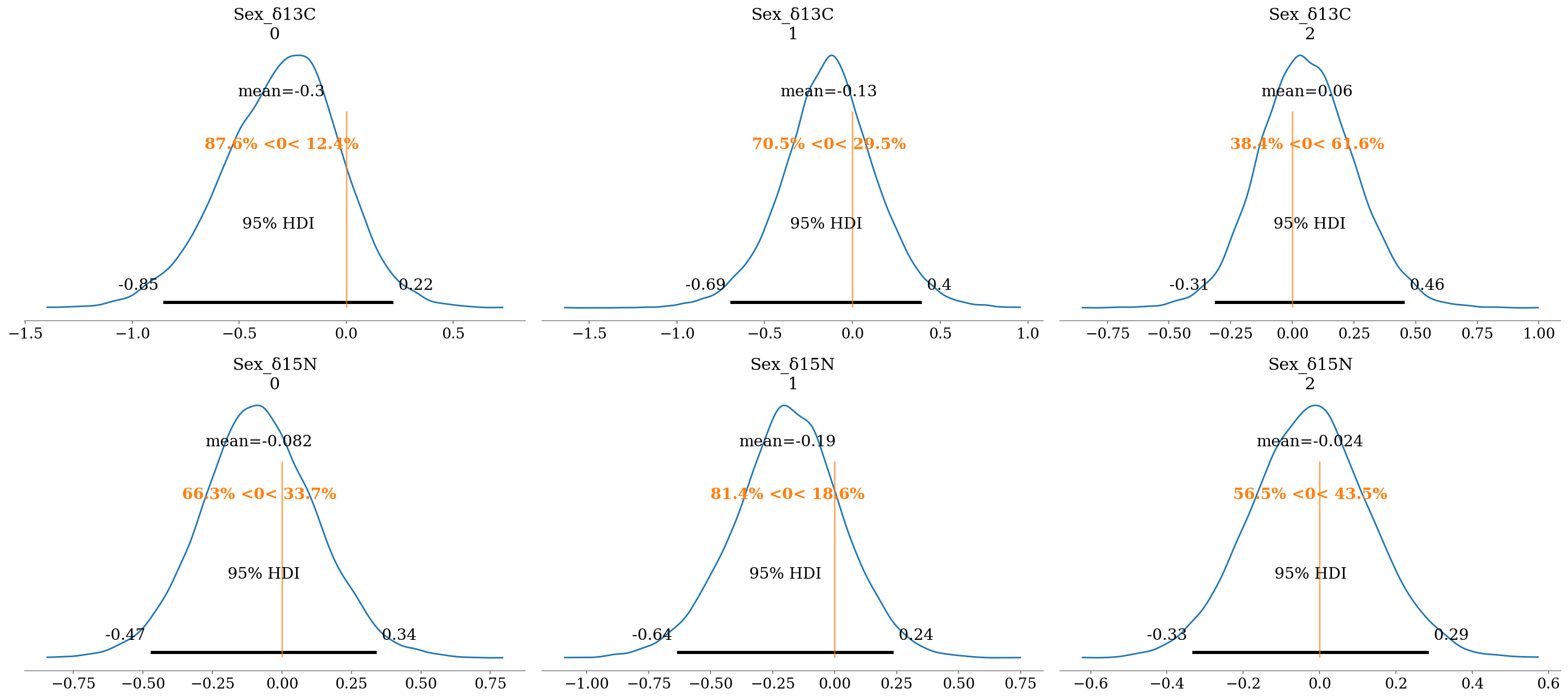
2.6.6.2 Season
The effect of the season was more evident, with \(P(\beta < 0 \lor \beta > 90)\%\) in most comparisons:
- \(\delta^{13}C\):
- H. dipterurus: Cold season with less negative values than the warm season, suggesting more oceanic habits during the latter.
- \(\delta^{13}C_w = \delta^{13}C - \beta\)
- \(\delta^{13}C_c = \delta^{13}C\); cold season with less negative values.
- H. dipterurus: Cold season with less negative values than the warm season, suggesting more oceanic habits during the latter.
- \(\delta^{15}N\): The three species showed less positive values during the cold season in relation to the warm season, which suggests that their prey had a higher trohpic position during the latter.
- \(\delta^{13}C_w = \delta^{13}C + \beta\)
- \(\delta^{13}C_c = \delta^{13}C\); cold season with less positive values.
The lowest \(P(\beta < 0 \lor \beta > 90)\%\) were found for N. entemedor (\(P \approx 70\%\)) and R. steindachneri (\(P \approx 60%\)) in \(\delta^{13}C\).
az.plot_posterior(full_mod, var_names = 'Season', filter_vars = 'like', ref_val = 0, hdi_prob = 0.95);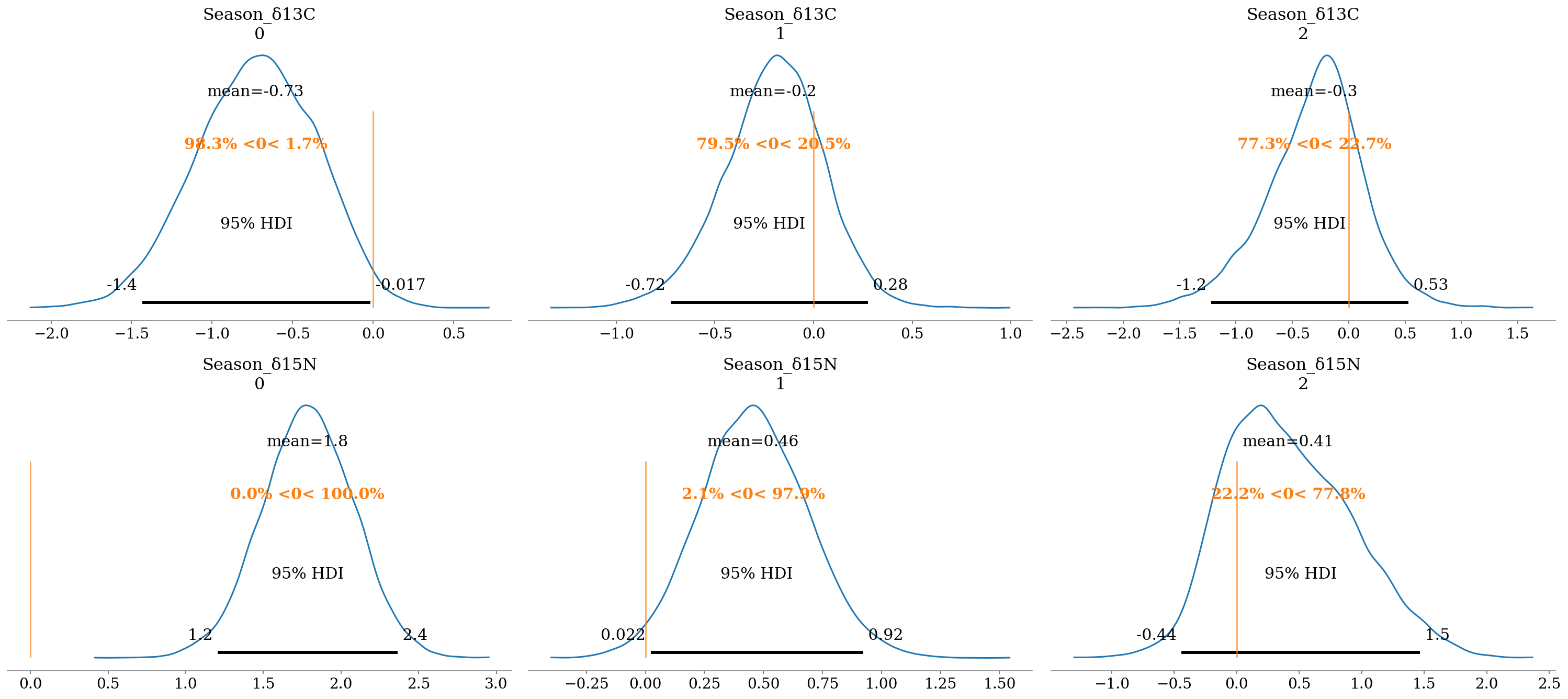
2.6.6.3 Maturity stages
There were high probabilities of differences between age categories, with the exception of R. steindachneri en \(\delta^{15}N\) (\(P(\beta>0) \approx 56\%\)). The rest of the comparisons had similar trends, in the sense that juveniles had lower values in both isotopes, suggesting more oceanic habitats and lower trophic positions. The only exception was H. dipterurus in \(\delta^{13}C\), whose juveniles had more coastal habits (less negative values).
- Interpretation a):
- \(\delta^{13}C\):
- \(\delta^{13}C_a = \delta^{13}C\)
- \(\delta^{13}C_j = \delta^{13}C - \beta\); juveniles had more negative values.
- \(\delta^{15}N\):
- \(\delta^{13}C_a = \delta^{15}N\)
- \(\delta^{13}C_j = \delta^{15}N - \beta\); juveniles had less positive values.
- \(\delta^{13}C\):
- Interpretation b):
- \(\delta^{13}C_a = \delta^{13}C\)
- \(\delta^{13}C_j = \delta^{13}C + \beta\); juveniles had more positive values.
az.plot_posterior(full_mod, var_names = 'Maturity', filter_vars = 'like',
ref_val = 0, hdi_prob = 0.95);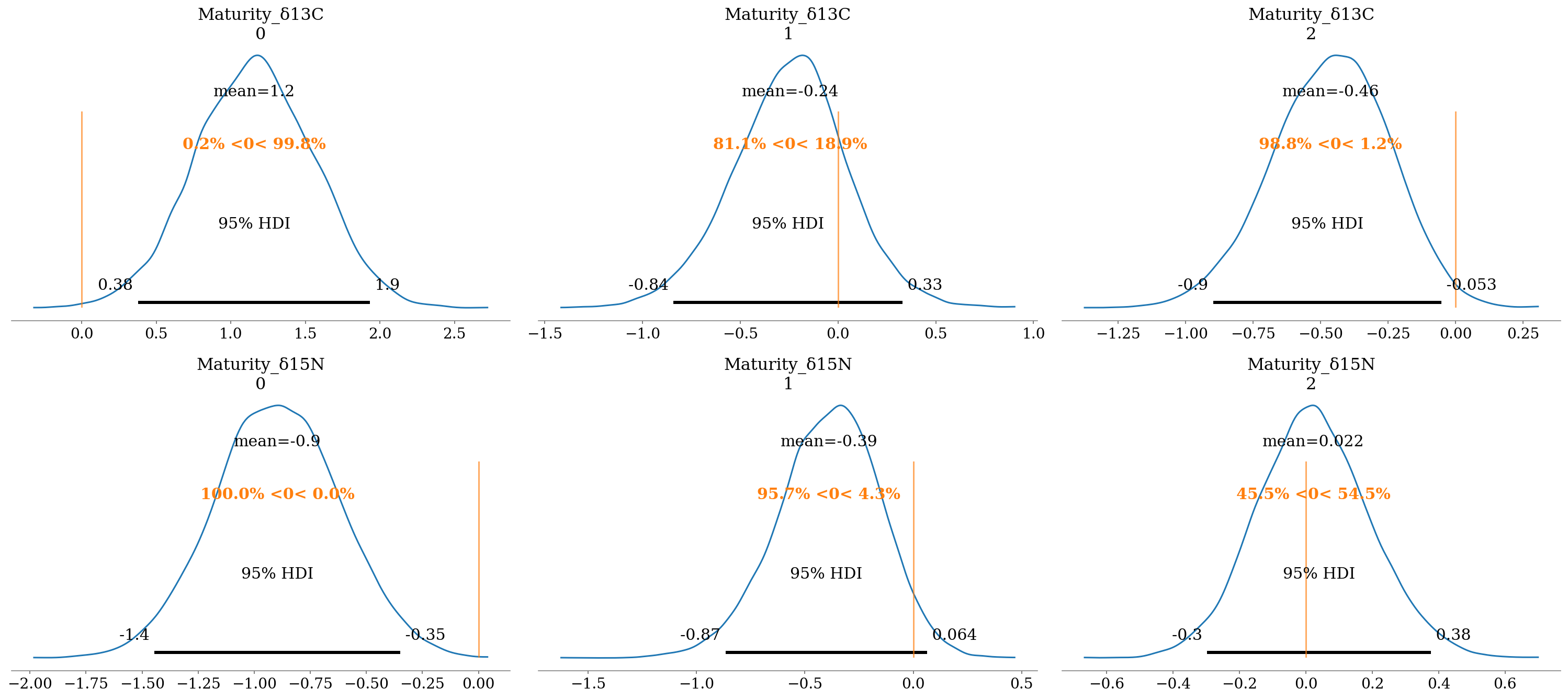
2.6.7 Together
These results can be presented in a more compact way using forest plots, where the lines represent the Highest Density Intervals (also called Credible Intervals). Thin lines represent the \(HDI_{95\%}\), thick lines the \(HDI_{50\%}\), and the points the mean of the distribution.
az.plot_forest(full_mod, hdi_prob = 0.95, var_names = '_δ15N', filter_vars = 'like', combined = True);
#plt.gcf().set_size_inches(4*1.61,4.5)
#plt.savefig(output_dir+'/figures/d15N_forestplot.pdf', format = 'pdf', bbox_inches = 'tight')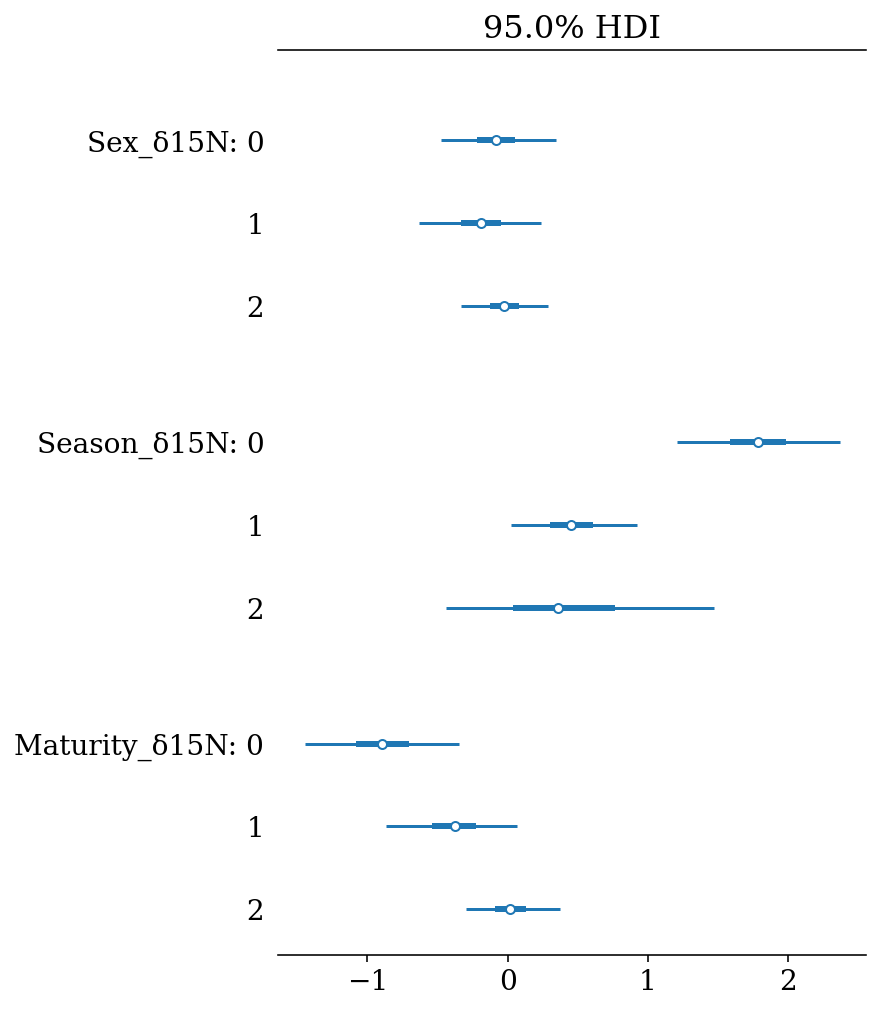
az.plot_forest(full_mod, hdi_prob = 0.95, var_names = '_δ13C', filter_vars = 'like', combined = True);
#plt.gcf().set_size_inches(4*1.61,4.5)
#plt.savefig(output_dir+'/figures/d13C_forestplot.pdf', format = 'pdf', bbox_inches = 'tight')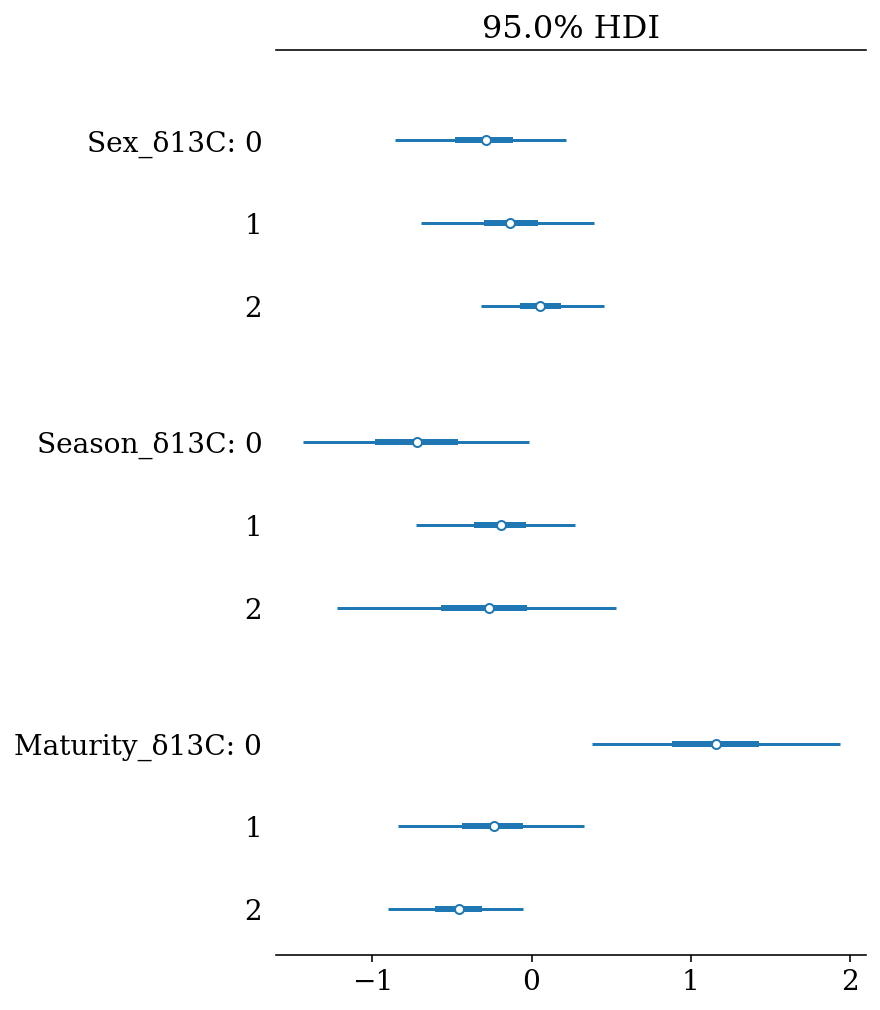
2.6.7.1 Isotopic mean comparison between species
Since in the process we also estimated the posterior distributions of the means for each species, we can also directly compare them by simply substracting them:
def compare_posteriors(mod, labels,
pars = ['µδ13C', 'µδ15N'],
isos = ['$\delta^{13}C$', '$\delta^{15}N$'],
save = False):
from itertools import combinations
# Get every comparison
spp = [i for i, sp in enumerate(labels)]
comps = list(combinations(spp, 2))
# Create a figure with two spaces for each combination
for i, comp in enumerate(comps):
_, ax = plt.subplots(1, 2, figsize = (10,6), constrained_layout = False,
sharex = False, sharey = False)
# For each parameter (isotope):
for j,par in enumerate(pars):
# Calculate the difference between posterior distributions
Diff = mod.posterior[par][:,:,comp[0]] - mod.posterior[par][:,:,comp[1]]
# Plot the difference, show the median of the distribution and P(Diff < 0 or Diff > 0)
az.plot_posterior(Diff, ref_val = 0, hdi_prob = 0.95, point_estimate = 'mean', ax = ax[j])
# Title for each panel is the isotope
ax[j].set_title(f'{isos[j]}')
# The title for each pair of comparisons is the pair of species
plt.suptitle(f'{labels[comp[0]]} vs. {labels[comp[1]]}')
if save is True:
plt.gcf().set_size_inches(4*1.61, 4)
plt.savefig(output_dir+'/figures/'+f'{labels[comp[0]]} vs. {labels[comp[1]]}.pdf',
format = 'pdf',
bbox_inches = 'tight')def forest_posteriors(mod, labels,
pars = ['µδ13C', 'µδ15N'],
isos = ['$\delta^{13}C$', '$\delta^{15}N$'],
var_names = None,
save = False):
from itertools import combinations
from xarray import Dataset, concat, merge
# Get every comparison
spp = [i for i, sp in enumerate(labels)]
comps = list(combinations(spp, 2))
Diffs = list()
comps_sp = list()
for j, par in enumerate(pars):
for i,comp in enumerate(comps):
# Calculate the difference between posterior distributions
Diff = mod.posterior[par][:,:,comp[0]] - mod.posterior[par][:,:,comp[1]]
Diffs.append(Diff)
comps_sp = [f'{labels[comp[0]]} - {labels[comp[1]]}' for comp in comps]
x_array = concat(Diffs, dim = 'iso')
x_array = x_array.values.reshape((2,3,3,5000))
x_array = Dataset(data_vars = {pars[0]: (['comp', 'chain', 'draw'], x_array[0,:,:,:]),
pars[1]: (['comp', 'chain', 'draw'], x_array[1,:,:,:])},
coords = {'iso': ['µδ13C', 'µδ15N'], 'comp': comps_sp})
#comps_sp = set(comps_sp)
az.plot_forest(x_array, combined = True,
#kind = 'ridgeplot',
#ridgeplot_alpha = 0,
#ridgeplot_truncate = False,
#ridgeplot_quantiles = [0.05, 0.5, 0.95],
hdi_prob = 0.95, var_names = var_names)In the following figures we can observe high probabilities of mean differences in almost every comparison. Summarising:
- \(\delta^{13}C\)
- N. entemedor > H. dipterurus (\(P = 100\%\))
- H. dipterurus < R. steindachneri (\(P \approx 54.4\%\))
- N. entemedor > R. steindachneri (\(P = 100\%\))
- \(\delta^{15}N\)
- N. entemedor < H. dipterurus (\(P = 100\%\))
- H. dipterurus > R. steindachneri (\(P \approx 100\%\))
- N. entemedor > R. steindachneri (\(P = 100\%\))
compare_posteriors(mod = full_mod,
labels = ['H. dipterurus', 'N. entemedor', 'R. steindachneri'],
save = False)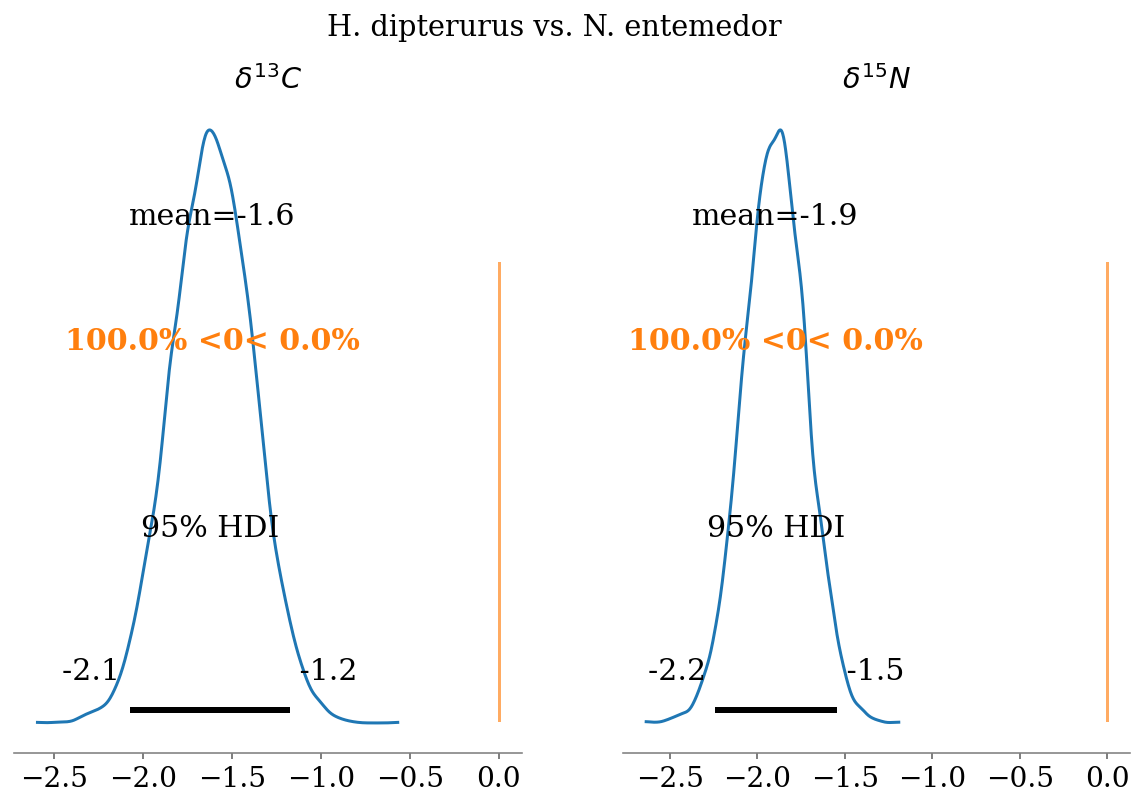
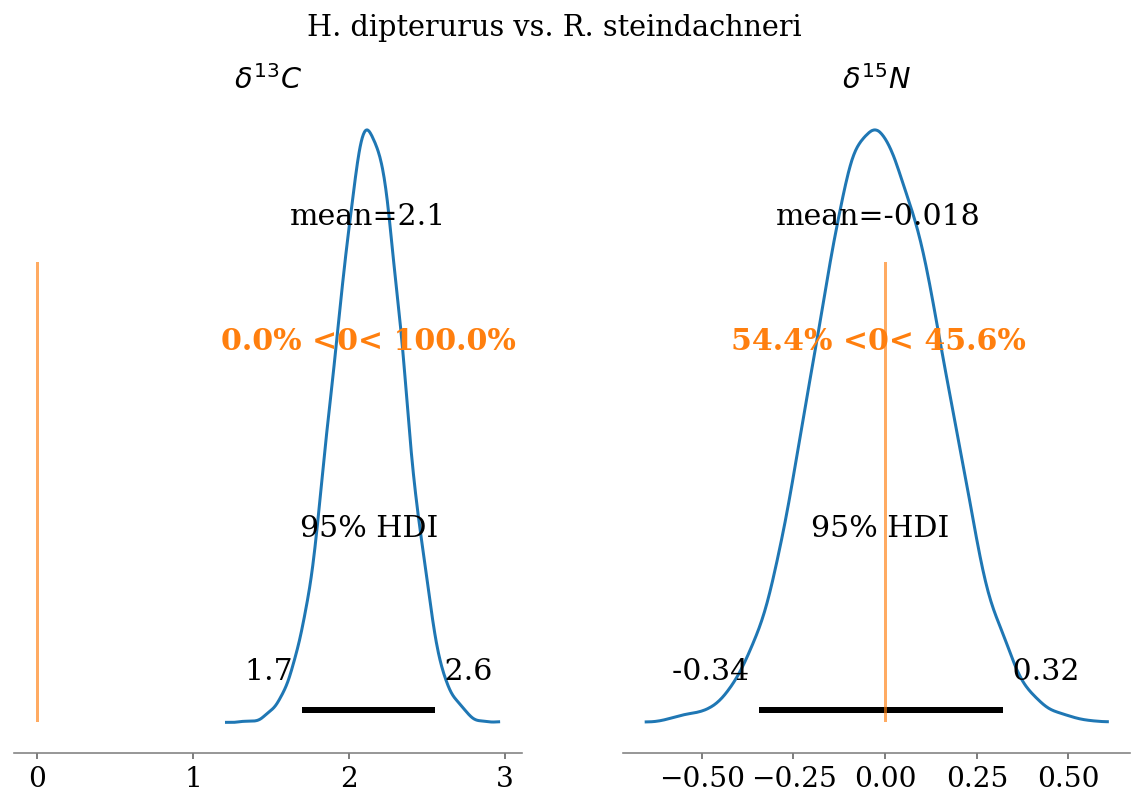
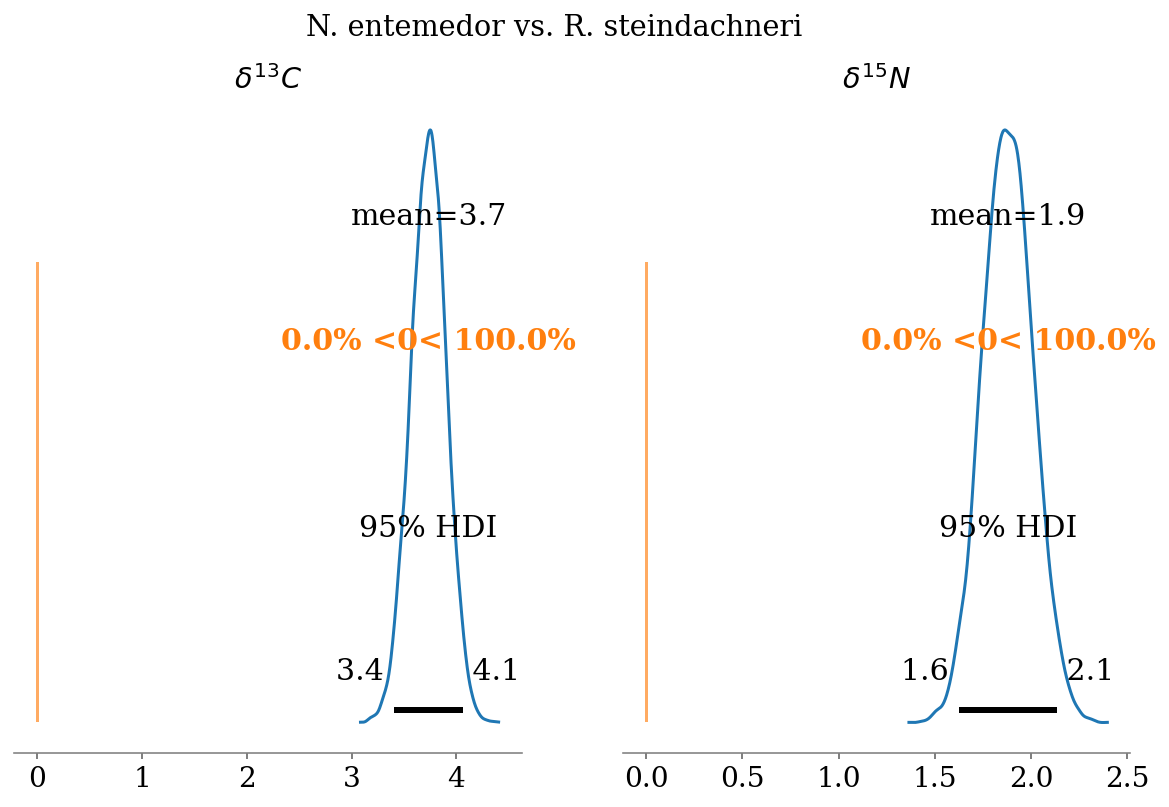
forest_posteriors(full_mod,
labels = ['HD', 'NE', 'RS'])
#plt.gcf().set_size_inches(4*1.61, 4)
#plt.savefig(output_dir+'/figures/mean_forestplot.pdf',
# transparent = True,
# format = 'pdf', bbox_inches = 'tight')
2.6.8 Bivariate Posterior Distribution
def plot_posteriors(data, mod, labels = None, group_col = 'Species', iso_cols = ['d13c', 'd15n'],
palette = 'Paired', shade = True,
pars = ['µδ13C', 'µδ15N'], isos = ['$\delta^{13}C$', '$\delta^{15}N$']):
from matplotlib.ticker import MaxNLocator
# To avoid re-indexing every time
x = iso_cols[0]
y = iso_cols[1]
# Empty Data Frame to store the posterior samples
samples = pd.DataFrame()
# Unique values of the group column to cicle through
groups = data[group_col].unique()
# Define limits of the plot
xlim = (data[x].min() - 0.5, data[x].max() + 0.5)
ylim = (data[y].min() - 0.5, data[y].max() + 0.5)
# Form a Data Frame with the posterior samples for each isotope
shape = mod.posterior[pars[0]].shape
for group in groups:
temp = pd.DataFrame({'d13c':mod.posterior[pars[0]][:,:,group].values.reshape(shape[0]*shape[1]),
'd15n':mod.posterior[pars[1]][:,:,group].values.reshape(shape[0]*shape[1]),
group_col: group})
samples = samples.append(temp, ignore_index = False)
samples = samples.reset_index(drop = True)
# Map value labels to a new column (if provided)
if type(labels) is dict:
data['Group'] = data[group_col].map(labels)
samples['Group'] = samples[group_col].map(labels)
group_col = 'Group'
# Plot the joint posterior distribution and its marginals
grid = sns.JointGrid(x = x, y = y, data = data, xlim = xlim, ylim = ylim)
g = grid.plot_joint(sns.scatterplot, hue = group_col, palette = palette, data = data, alpha = 0.7)
sns.kdeplot(x = samples[iso_cols[0]], shade = True, thresh = 0.05, hue = samples[group_col],
ax = g.ax_marg_x, palette = palette, legend = False)
sns.kdeplot(y = samples[iso_cols[1]], shade = True, thresh = 0.05, hue = samples[group_col],
ax = g.ax_marg_y, palette = palette, legend = False)
sns.kdeplot(x = samples[iso_cols[0]], y = samples[iso_cols[1]], shade = shade, thresh = 0.05,
hue = samples[group_col], palette = palette, legend = True, cbar= False,
alpha = 0.7, ax = g.ax_joint)
# Change the appearance of the plot
g.ax_joint.set_xlabel(isos[0])
g.ax_joint.set_ylabel(isos[1])
g.ax_joint.xaxis.set_major_locator(MaxNLocator(5))
g.ax_joint.yaxis.set_major_locator(MaxNLocator(5)) Given that both isotopes were modeled at the same time, we can plot the joint posterior mean distribution, which is non-orhtogonal as if both isotopes were independent from one another (separate Generalized Linear Models or independent null hypothesis testing). It is important to remark that the means are not in the centroid of each group. This is a favorable consequence of having used Student-T distributions for the parameters and likelihood instead of normal distributions. By stablishing that extreme values have a higher probability than in a normal distribution, the effect of the more extreme values is disregarded or, in another words, in a normal distribution they have low probabilities and, hence, each point is given a heavier weight.
This consequence is why using heavy-tailed distributions is called robust regression. In this example the effect is shown in a linear regression with a continuous covariate, in which the robust estimation of the parameters is not “deceived” by the more extreme values on the y variable and posterior predictive lines are closer to the real line than those of the “normal” regression.
plot_posteriors(data = glm_data, mod = full_mod,
labels = {0: 'H. dipterurus', 1: 'N. entemedor', 2: 'R. steindachneri'},
palette = colors[0:3])
#plt.gcf().set_size_inches(4, 4*1.61)
#plt.savefig(output_dir+'/figures/posterior_means.pdf', format = 'pdf', bbox_inches = 'tight')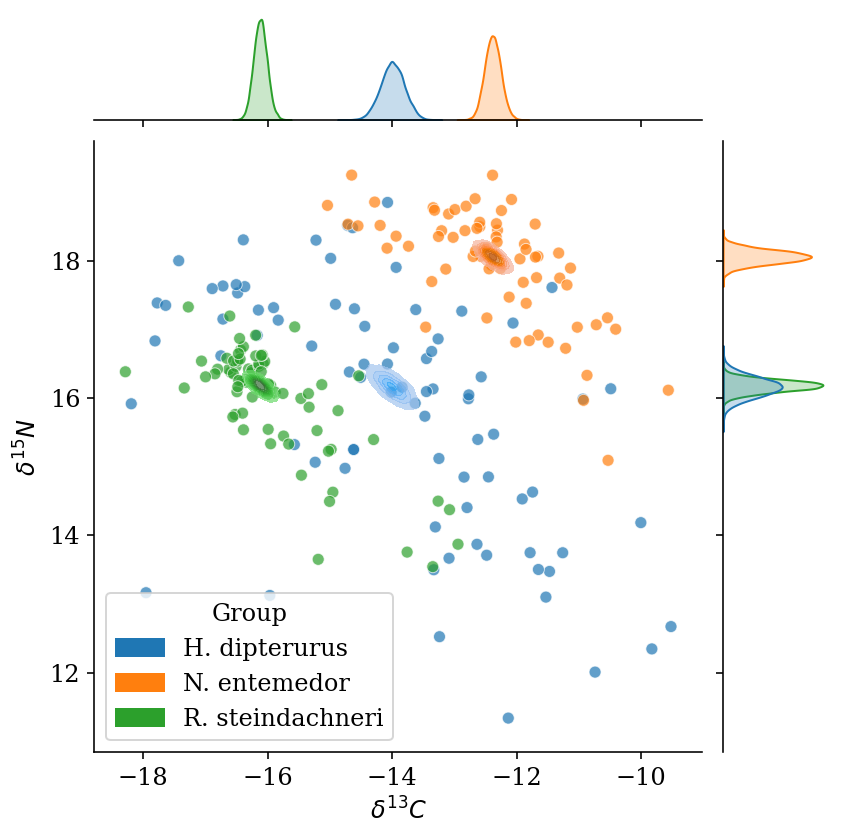
Note
End of notebook
%load_ext watermark
%watermark -n -u -v -iv -wLast updated: Sat Jun 03 2023
Python implementation: CPython
Python version : 3.8.6
IPython version : 7.19.0
seaborn : 0.11.0
matplotlib: 3.3.3
numpy : 1.19.4
pymc3 : 3.11.2
arviz : 0.11.2
theano : 1.1.2
pandas : 1.1.5
Watermark: 2.1.0