Aunque me gustaría entrar directamente al tema de pruebas de hipótesis, es necesario que empecemos por entender qué hipótesis es la que estamos probando, y lo que es la inferencia estadística.
9.1 Hipótesis
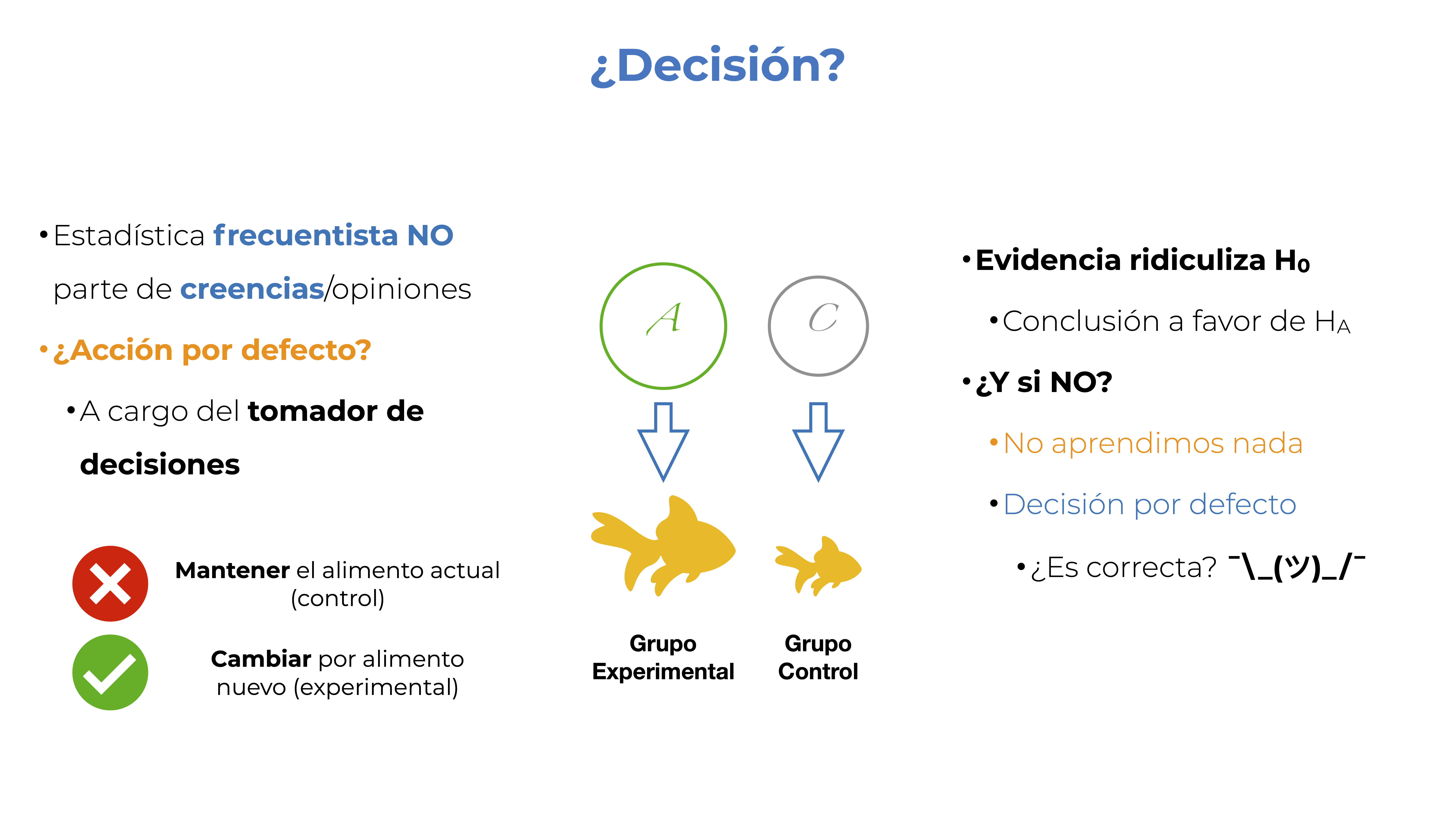
Si yo te preguntara ¿qué es una hipótesis? Yo esperaría una respuesta cercana a “una posible explicación a un fenómeno”. La definición “completa” que me gustaría que recordaras es “una serie de premisas concatenadas para dar una explicación a un fenómeno”, de la forma “Dado que A, entonces B” (¿recuerdas la probabilidad condicional?). Bueno, pues es importante reconocer que esa NO es la hipótesis que probamos con las pruebas de significancia, o al menos no directamente. Si a nosotros nos interesa saber si un nuevo alimento, llamémosle A, es capaz de darnos peces más grandes que nuestro alimento actual (control, C), entonces diseñaríamos un experimento con dos grupos: un grupo experimental al que le daríamos el alimento A, y un grupo control al que se le daría el alimento C. Nuestra hipótesis sería algo como “Dadas las diferentes composiciones de los alimentos A y C, la talla final será diferente entre ambos grupos”. Esa es nuestra hipótesis de trabajo; es decir, nuestra posible explicación; sin embargo, esta no es una hipótesis estadística.
¿Qué es entonces una hipótesis estadística? Sería más correcto hablar de juegos de hipótesis estadísticas, el cual quedaría de la siguiente manera:
Entonces, es un juego porque hay más de una, y representan un escenario de igualdad o de diferencia. Por cada juego de hipótesis hay al menos una hipótesis de nulidad (\(H_0\)) y una hipótesis alternativa (\(H_1\)). ¿Cómo llegamos a estas hipótesis y qué representan? Bien, es ahí donde debemos de hablar de las pruebas de significancia estadística.
Nota
Los términos “pruebas de hipótesis de nulidad” y “pruebas de significancia estadística” hacen referencia a lo mismo; es decir, son sinónimos para referirnos al proceso mediante el cual utilizaremos a la estadística para tomar una decisión.
9.2 Pruebas de hipótesis de nulidad
En el Capítulo 1 dimos algunas definiciones de estadística, pero hay una que, toma mucho sentido en el tema que vamos a abordar hoy. Esta fue propuesta por Savage (1954): “[La estadística] es la ciencia de tomar decisiones bajo situaciones de incertidumbre.
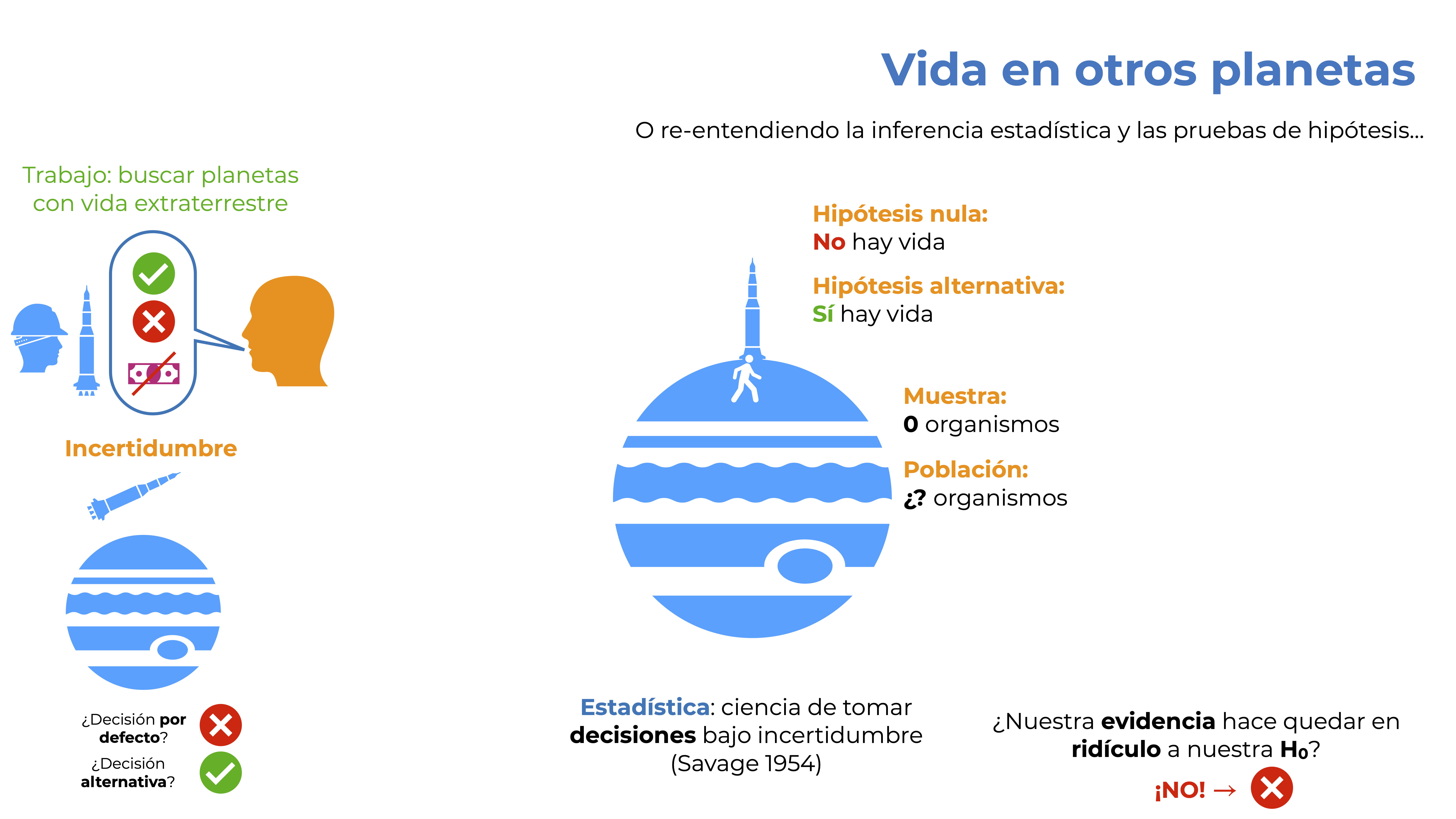
Partiendo de esa definición, entendamos qué es la inferencia estadística y las pruebas de hipótesis, utilizando una analogía propuesta por Cassie Kozyrkov (científica jefa de decisión en Google). Pensemos que logramos contratarnos en una empresa de exploración espacial, y que nuestra actividad principal es salir al espacio en una nave espacial, visitar planetas y reportar si hay vida o no.
Figura 9.1: A buscar planetas.
¿Bonito? Tal vez demasiado para ser verdad y, como era de esperarse, lo es. Tenemos un jefe con una actitud bastante mejorable, pero dejando eso de lado, tenemos algunas limitaciones logísticas:la primera es que nuestro reporte es a través de un aparatito que cuenta con dos botones uno para decir que sí hay vida y otro para decir que no hay vida en un planeta dado, otra limitación es que tenemos recursos limitados y que únicamente podemos hacer caminatas de dos horas. Esto se traduce en que estamos en una situación de incertidumbre.
Figura 9.2: Exploración espacial e incertidumbre.
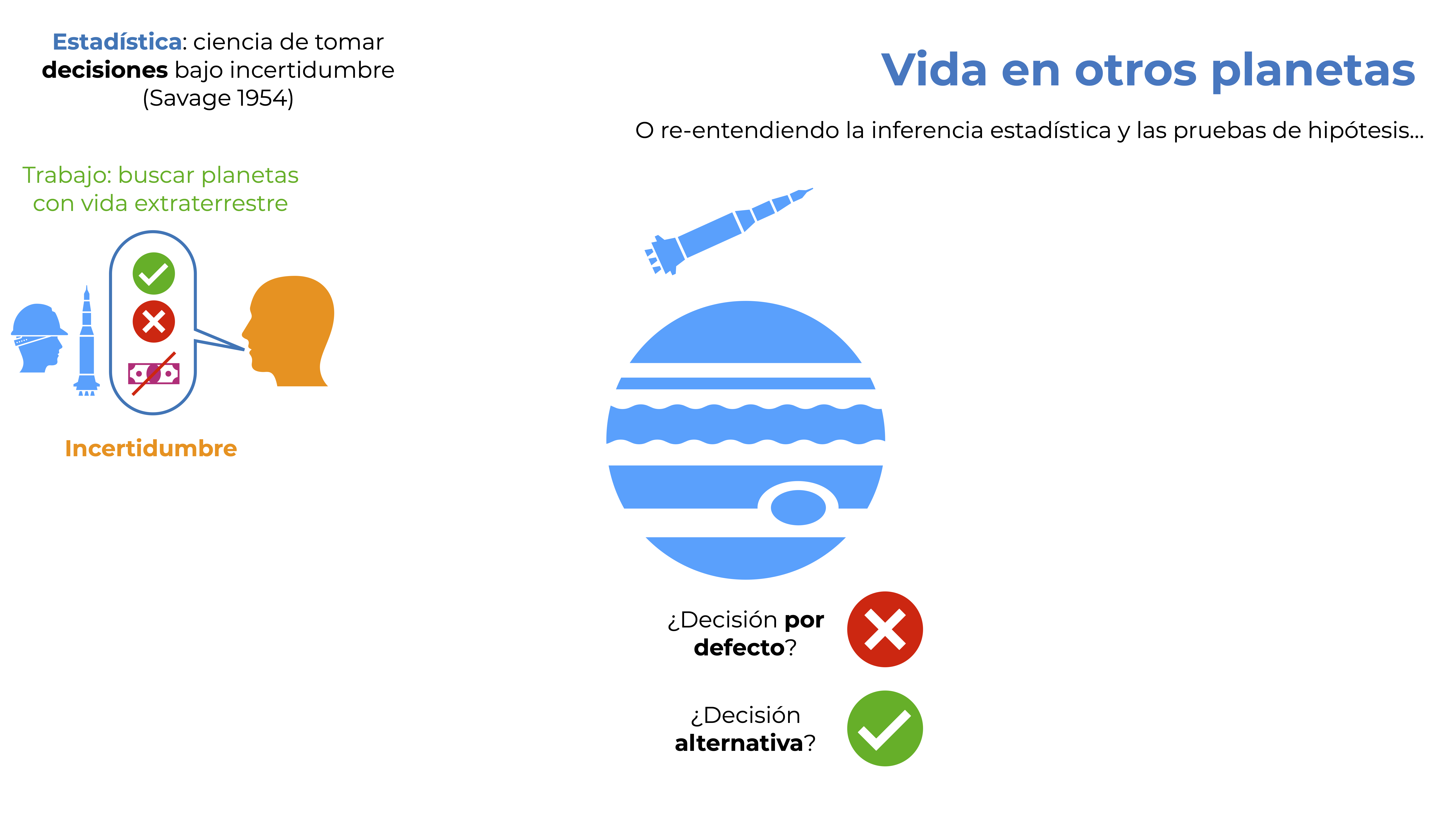
Un desafío más es que NO podemos ver un planeta y no dar un reporte. Debemos, sí o sí, decir si hay vida en el planeta o no. Esto lleva a que necesitemos establecer una decisión por defecto. ¿Por defecto para qué? Para aquellos casos en los que NO podamos aterrizar en el planeta y explorarlo (tal vez hay una tormenta eléctrica, o alguna otra situación). Estarás de acuerdo conmigo en que decir que NO hay vida en el planeta tiene más sentido que decir que sí, y no por la situación del planeta en si misma, sino porque de lo contrario no tiene caso hacer una exploración espacial. Me explico. Si la acción por defecto fuera decir que sí hay vida en el planeta no necesitariamos ni siquiera hacer exploraciones, simple y sencillamente presionaríamos el botón correspondiente cada que nos avisaran de un nuevo planeta.
Figura 9.3: Decisiones por defecto y alternativa.
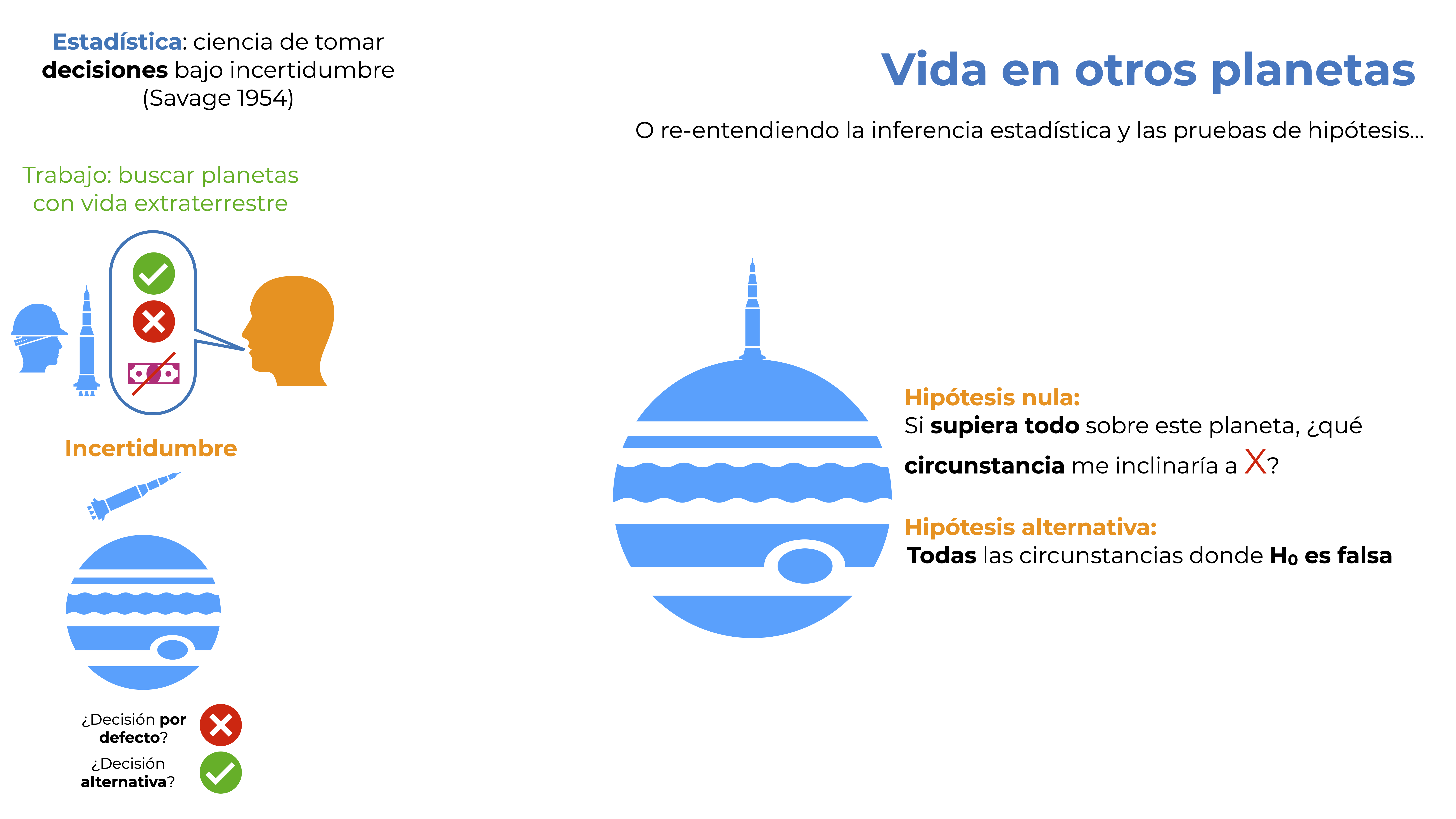
Una vez planteadas nuestras decisiones por defecto, podemos pensar en probar si hay vida en el planeta o no. Esto es un escenario típico de una prueba de hipótesis de nulidad, lo que nos lleva a definir una hipótesis nula y una alternativa. Para nuestra hipótesis nula nos podemos preguntar:
“Si supiera todo sobre este planeta, ¿qué me inclinaría a presionar el botón X?”.
Espero que tu respuesta haya sido “Que no haya vida en el planeta”. Simple, ¿no? A final de cuentas lo sabemos TODO sobre el planeta, incluyendo si hay vida o no y en consecuencia presionaremos el botón X si y solo si no hay vida. ¿Y la hipótesis alternativa? Pues está dada por todas las situaciones en las que la hipótesis nula sea falsa, en este caso que sí haya vida en el planeta.
Entonces, definimos nuestras hipótesis:
Nula (\(H_0\)): No hay vida en el planeta.
Alternativa(\(H_A\)): Sí la hay.
Figura 9.4: Hipótesis de nulidad e hipótesis alternativa.
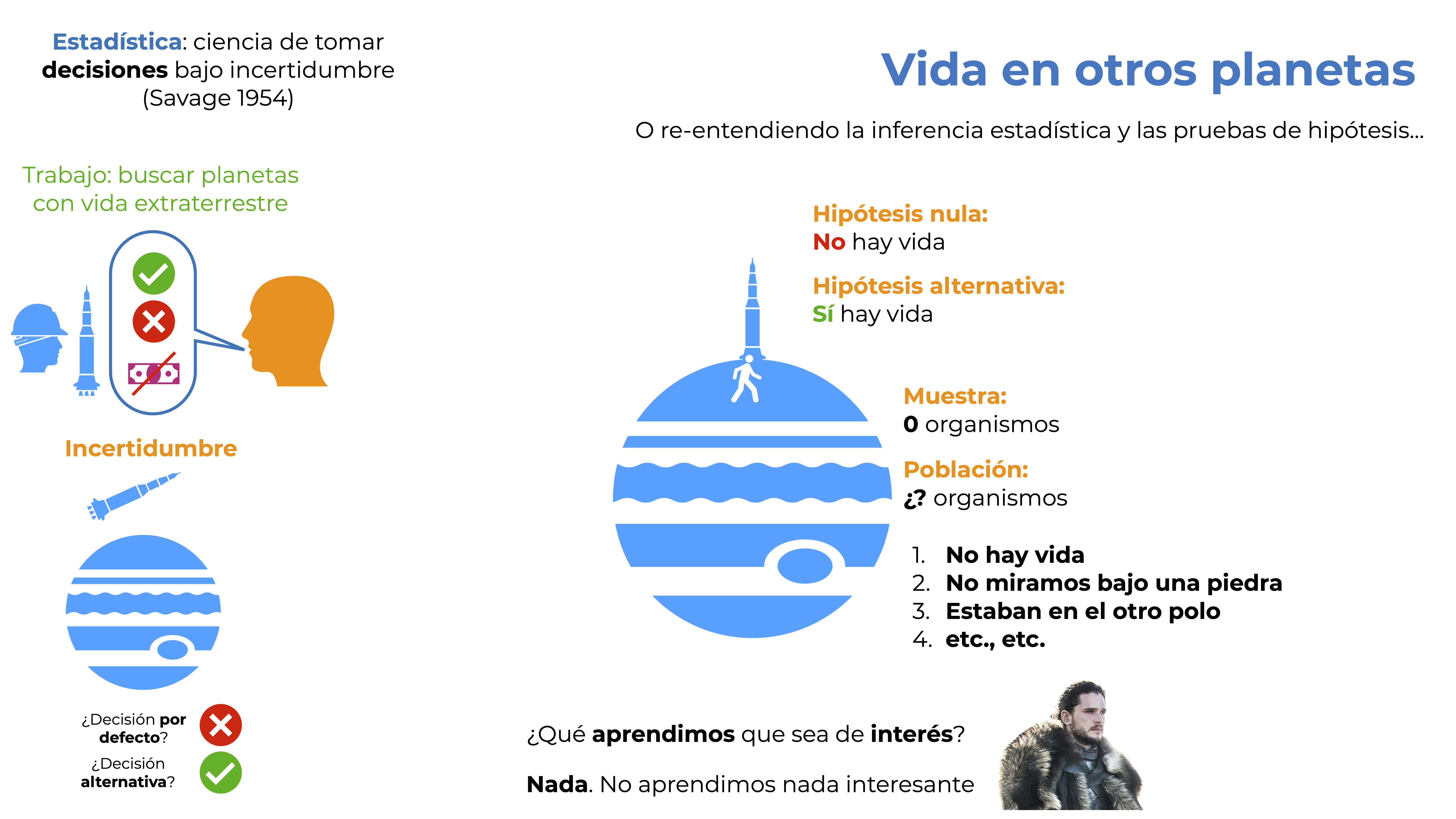
Salimos entonces a explorar el universo, encontramos un planeta, aterrizamos y damos nuestra caminata. El resultado: 0 organismos en las dos horas que caminamos. Te pregunto: ¿qué aprendimos que sea de interés? Y aquí espero que tu respuesta sea Nada. Me explico, tuvimos una muestra de 0 organismos, no sabemos de qué tamaño es la población (si es que la hay). ¿Explicaciones para el resultado? Bastantes, pero todo se reduce a que tuvimos que tomar nuestra decisión por defecto y, por lo tanto, no aprendimos nada del planeta. Literalmente obtuvimos el mismo resultado que si hubieramos pasado de largo y eso está bien. No entraré en la discusión de por qué el buscar siempre aprender algo es un sinsentido, solo diré que quien quiera hacerlo es porque tiene demasiada energía, pero sigamos con nuestro ejemplo.
Figura 9.5: No sabes nada, Jon Snow.
Recordemos la definición de Savage y tomemos una decisión. Para ello cambiemos nuestra pregunta a lo que debería de ser el mantra detrás de todas las pruebas de hipótesis: ¿Mi evidencia deja en ridículo a mi hipótesis de nulidad? La respuesta debería de ser no, pues no encontramos nada que la contradijera y, por lo tanto, presionaremos nuestro botón de no hay vida en el planeta.
Figura 9.6: ¿Nuestra evidencia hace quedar en ridículo a nuestra \(H_0\)?
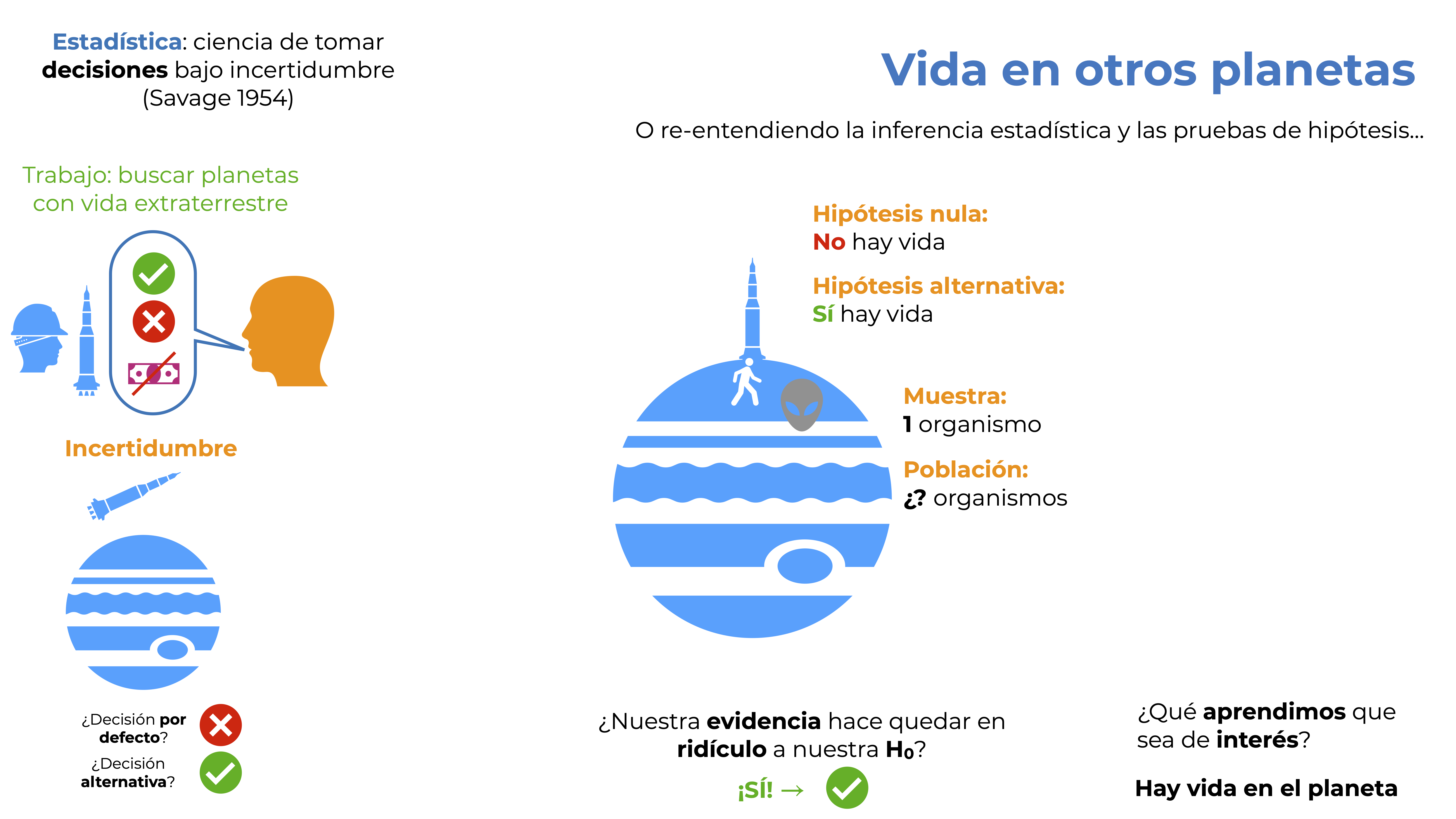
Salimos del planeta y llegamos a otro. Repetimos el proceso, solo que aquí sí nos encontramos una forma de vida alienígena en forma de exactamente un individuo. Recordemos nuestro marco de decisión. Nuestra acción por defecto es presionar el botón X si no hay vida (hipótesis nula) y acabamos de encontrar un individuo (solo uno). ¿El tamaño de la población? No lo sabemos. ¿Nuestra evidencia deja en ridículo a nuestra hipótesis nula? Por supuesto que sí, entonces la rechazamos y tomamos nuestra acción alternativa: presionar el botón con la palomita verde. ¿Qué aprendimos que sea de interés? Que hay vida en el planeta.
Figura 9.7: ¡Aprendimos algo!
Este ejemplo es lo que hacemos o deberíamos de hacer al aplicar una prueba de hipótesis de nulidad. Establecer nuestra acción por defecto y la alternativa, definir nuestra hipótesis de nulidad, ir a tomar datos y luego preguntarnos si esa evidencia deja en ridículo a nuestra hipótesis nula. ¿Cómo definimos la acción por defecto? Eso es tarea del tomador de decisiones, y en la academia muy pocas veces las tenemos definidas. ¿Cómo concluimos? Si nuestra evidencia ridiculiza a nuestra hipótesis nula, tendremos una conclusión a favor de la hipótesis alternativa. ¿Si no? No aprendimos nada y tomamos la decisión por defecto. ¿Es la correcta? No lo sabemos, pero tampoco nos interesa… o al menos hasta cierto punto. Es aquí donde entran los tipos de errores y los valores de p, solo recuerda: buscar tus llaves antes de salir de casa y no encontrarlas después de 5 minutos NO indica que no estén, solo no sabes dónde están.
Figura 9.8: Alimento experimental vs. control
9.3 Tipos de errores
Ahora bien, el no poder responder inequívocamente a si nuestra decisión fue la correcta o no es lo que nos lleva a hablar de los tipos de errores estadísticos. En el Capítulo 7 hablamos de algunos errores de muestreo (sistemático y aleatorio), pero estos son diferentes a los errores que podemos cometer al momento de realizar nuestras pruebas de significancia. Estos errores los vamos a expresar en términos de probabilidades. ¿Probabilidades de qué? Por muy “obvio” que parezca, probabilidades de equivocarnos al tomar una decisión sobre nuestra hipótesis de nulidad. Te voy a presentar estos errores de dos maneras: una formal, otra que pudiera resultarte más intuitiva, y una analogía. Formalmente:
Error de tipo I (\(\alpha\)): Probabilidad de rechazar la hipótesis nula cuando es verdadera.
Error de tipo II (\(\beta\)): Probabilidad de NO rechazar la hipótesis nula cuando es falsa.
Si recuerdas nuestro viaje espacial y el proceso mediante el cual decidíamos si había vida en un planeta o no, todo se reduce a si nos quedamos con nuestra decisión por defecto (no rechazar la hipótesis de nulidad) o si nuestra evidencia la dejó en ridículo (rechazar la hipótesis de nulidad). Si te es posible, procura recordar estas definiciones. ¿Por qué digo que si te es posible? Porque puede ser que no te acomode pensar en términos de “rechazo” y que prefieras pensar en términos de aceptación. Bajo ese esquema tendríamos:
Error de tipo I (\(\alpha\)): Probabilidad de aceptar la hipótesis aternativa siendo falsa.
Error de tipo II (\(\beta\)): Probabilidad de aceptar la hipótesis nula siendo falsa.
Advertencia
La definición de los tipos de errores estadísticos está formalmente en términos de rechazar o no la hipótesis de nulidad. Este re-planteamiento en forma de aceptación es solo una herramienta didáctica. ¿Por qué? Porque nunca “aceptamos” o damos algo por cierto si es que estamos en un escenario de incertidumbre. Este re-planteamiento tiene solo un fin didáctico.
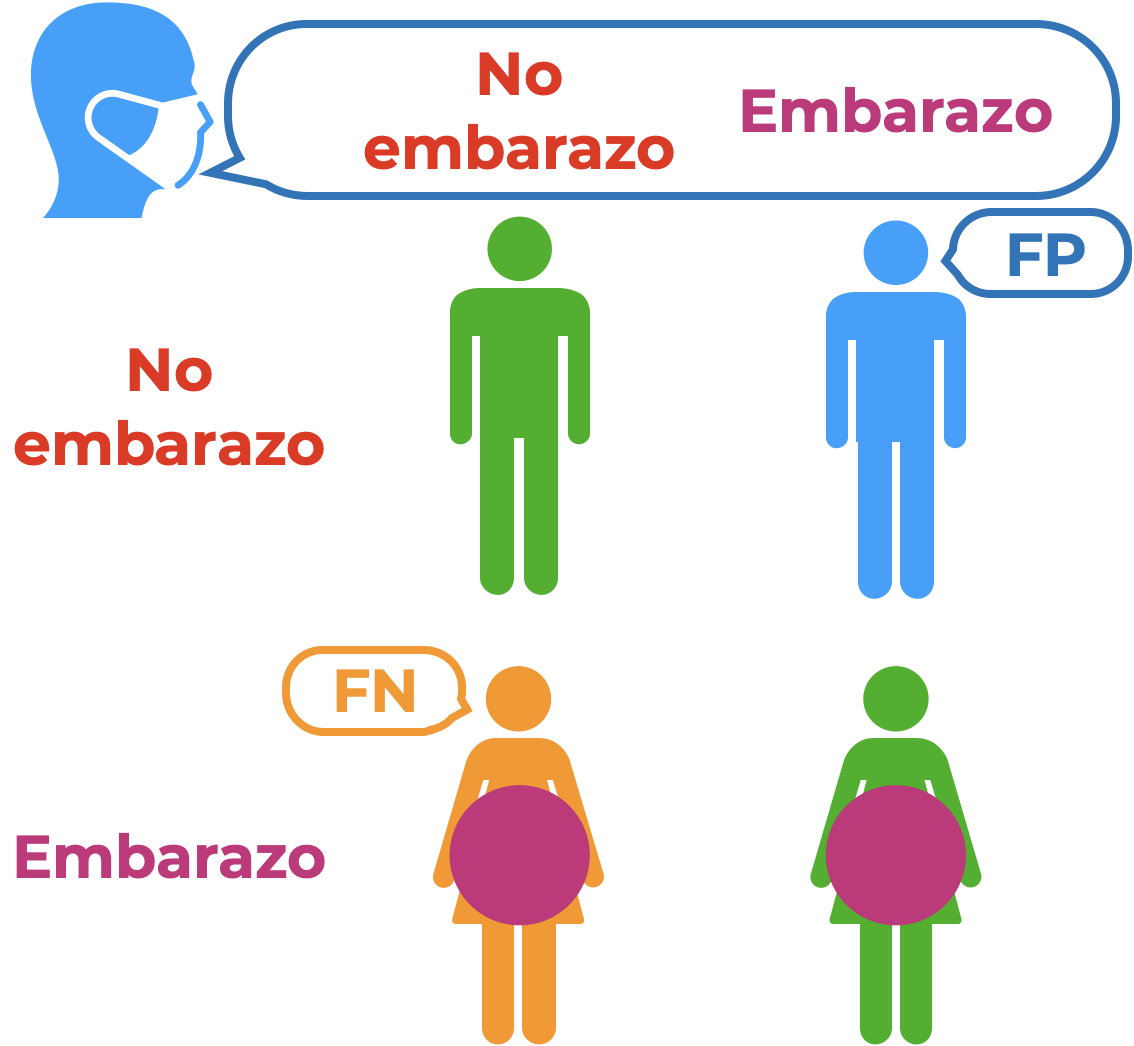
Ahora bien, hay una tercera forma de entender estos errores, la cual simplifica mucho las cosas. Imagina un escenario en el que van una mujer evidentemente embarazada y, por alguna extraña razón, un hombre a hacerse una prueba de embarazo. El doctor puede, entonces, dar dos veredictos por caso: la persona está embarazada o no está embarazada. Gráficamente esto podemos ponerlo de la siguiente manera:
Figura 9.9: Errores y falsedades.
Que un hombre esté embarazado es imposible, por lo que decirle a nuestro curioso paciente que lo está es un falso positivo o un error de tipo I. Por otra parte, decirle a la mujer que está embarazada que no lo está es un falso negativo, o un error de tipo II.
Aunque estos son los dos tipos de errores estadísticos formales, tenemos un tercero que, aún no siendo normal, es necesario que cuidemos:
Error Tipo III: Rechazar correctamente la hipótesis nula equivocada.
¿A qué me refiero con esto? A utilizar la matemática correcta para responder una pregunta equivocada; es decir, utilizar pruebas que no responden o atacan directamente nuestro problema. Un ejemplo de esto puede ser utilizar un modelo lineal simple para describir una relación exponencial, pero hablaremos de estos problemas más adelante.
Ahora bien, hablamos de probabilidades, mientras que en el ejemplo de la Figura 9.9 vimos errores particulares. Pues es aquí donde entra el famosísimo (¿infame?) valor de p.
9.4 Nivel de significancia
Si te pregunto ¿qué es el valor de p y qué representa? Es posible que busques la definición funcional y que me digas que es un valor que si es menor a 0.05 indica que la prueba es “significativa” y que si es mayor no lo es. Eso es solo la regla de decisión, pero no define al valor de p.
¿Qué es entonces? Retrocedamos un poco a nuestro ejemplo de la exploración espacial. Partíamos del supuesto (decisión por defecto) de que no hay vida en ningún planeta, y que nuestra evidencia debe de ridiculizar a nuestra hipótesis de nulidad para que presionemos el botón de que sí hay vida en el planeta. En nuestras pruebas de significancia es exactamente lo mismo. Partimos del supuesto de que no hay un efecto (o diferencia) significativa. Esto lo representamos con un modelo teórico de distribución de probabilidades, el cuál representa un universo donde la hipótesis nula siempre es verdadera. Es decir, esta distribución teórica de probabilidades son todos los casos en los cuales NO existe ningún efecto o diferencia entre nada. Un mundo gris y aburrido, vamos.
En este escenario entonces nosotros buscamos evidencia que nos haga cambiar de opinión, y lo evaluamos en términos probabilísticos lo evaluamos como la probabilidad de que el modelo teórico haya generado los datos que estamos viendo. ¿A que esto tiene más sentido que solo la regla de decisión?
Ahora puede que te preguntes: ¿de dónde sale esta probabilidad? Pues está definida por un estadístico de prueba. Tomando nuestros datos vamos a calcular el valor que les corresponde según la función del modelo teórico. Luego, vamos a obtener la probabildiad de encontrar, de forma aleatoria, ese valor, o uno con la misma probabilidad, o una menor. Ahora bien, si recuerdas algo de la sesión de probabilidad puede que esta última definición no te cuadre, y es que si tenemos una distribución continua no podemos buscar la probabilidad individual de un valor, por lo que la reformulamos como la probabilidad de encontrar otro valor al menos igual de grande, y esto es lo que conocemos como el nivel de significancia.
Importante
Valor de p, p-value y nivel de significancia son exactamente lo mismo, solo que algunas personas utilizan “nivel de significancia” para referirse al valor de \(\alpha\); e.g., “las pruebas se consideraron significativas a un nivel de significancia \(\alpha = 0.05\). Esto es erróneo, pues \(\alpha\) representa la probailidad de cometer un error de tipo 1 con la que estamos dispuestos a vivir, pero vamos a entrar a más detalles un poco más adelante.
Sé que esta última parte es sumamente abstracta, así que grafiquemos una distribución normal con un algunas áreas bajo la curva (probabilidades) de referencia:
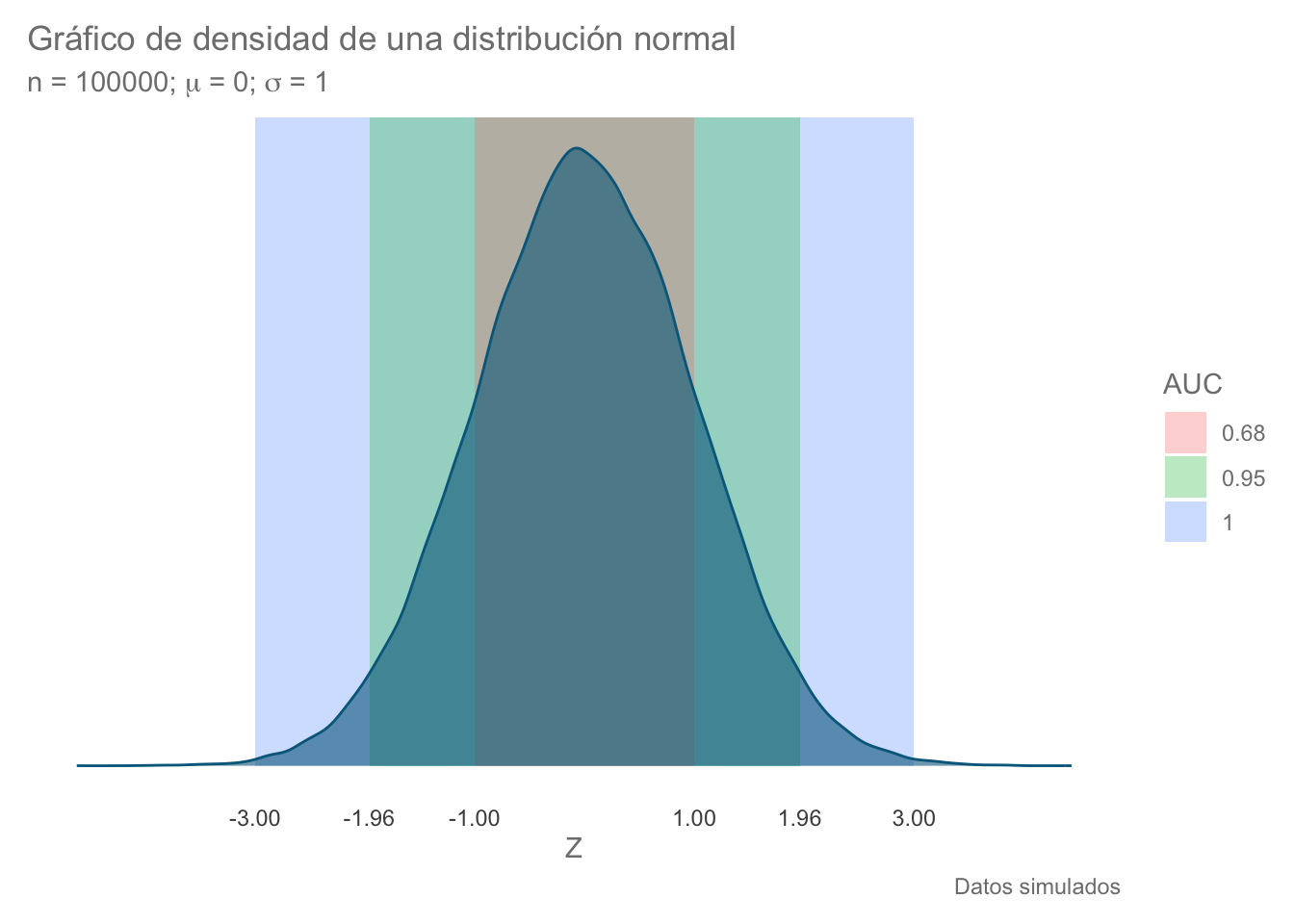
Figura 9.10: Áreas bajo la curva (AUC) para tres valores de Z de referencia. Estas representan las zonas de aceptación, con su amplitud (confianza) dada por el valor de AUC.
¿Qué nos dice este gráfico? Imagina que hacemos el procedimiento estadístico correspondiente y obtenemos un valor de \(Z = 1.0\). El área comprendida entre \(Z = 1\) y \(Z = -1\) es del 0.68. ¿Esto quiere decir que nuestro valor de p es de 0.68? NO, todo lo contrario. Recuerda, buscamos un valor al menos igual de grande; por lo tanto, nos interesa lo que está fuera de la zona sombreada (buscamos valores \(|Z| \geq 1\)) y entonces nuestro valor de \(p = 1-0.68 = 0.32\). ¿Es suficiente una probabilidad del 32% para decir que nuestra evidencia dejó en ridículo a nuestra hipótesis de nulidad? Creo que estarás de acuerdo conmigo en que no.
Pero volvamos a nuestro gráfico. Las zonas sombreadas representan las zonas de no rechazo a distintos niveles de “confianza”, de manera que si obtenemos un valor de Z (estadístico de prueba) \(\leq 1\) estamos en el intervalo de confianza del 68%, \(\leq 1.96\) del 95% y \(\leq 3\) de \(\approx\) 99%.
Imagina que ahora obtuvimos un valor de \(Z = 1.97\), recuerda lo que vimos en la sesión de probabilidad sobre el uso de la distribución normal en R. ¿Qué valor de \(p\) le corresponde? ¿Es un resultado “significativo? ¿Qué tal con \(Z = 1.95\)?
Esto me llevaría al siguiente punto de discusión, sobre el obscurantismo alrededor del valor de p, pero tomemos un desvío para hablar sobre otro concepto muy relacionado con este último: los intervalos de confianza
9.5 Intervalos de confianza
Los intervalos de confianza, como recordarás que mencionamos someramente en el Capítulo 8, representan una medida de incertidumbre en alguna estimación, pero vayamos más a fondo. Estos intervalos, al igual que el valor de p, abordan el mismo problema: las estimaciones puntuales no son infalibles ni siempre son verídicas, por lo que necesitamos una referencia de “certeza” alrededor de ellas. Si lo piensas detenidamente eso justamente es lo que hacemos con el valor de p y, de hecho, podemos pensar en los intervalos de confianza como el valor de p visto desde otra perspectiva.
Entonces, ¿qué son los intervalos de confianza? Son una referencia de la “certeza” que tenemos alrededor de una estimación. Es muy posible que te hayas encontrado con la notación \(\overline{x} ± SD\), en la cual resumimos nuestros datos con el promedio y la desviación estándar de los datos. Esto está bien siempre y cuando solo nos interese describir todos nuestros datos. Si nos interesa dar información sobre nuestra estimación, entonces haríamos algo tal que \(\overline{x}; [IC_i, IC_s]\), donde \(IC_i\) representa el límite inferior del intervalo de confianza e \(IC_s\) el límite superior.
Estos límites indican entre dónde y dónde (o, mejor dicho, entre qué valores) se puede encontrar la estimación. Si son equivalentes al valor de p, entonces siguen también un modelo teórico de distribución de probabilidades, y su amplitud está dada por un porcentaje de esa distribución (igual que en la zona de no rechazo de una hipótesis de nulidad).
Advertencia
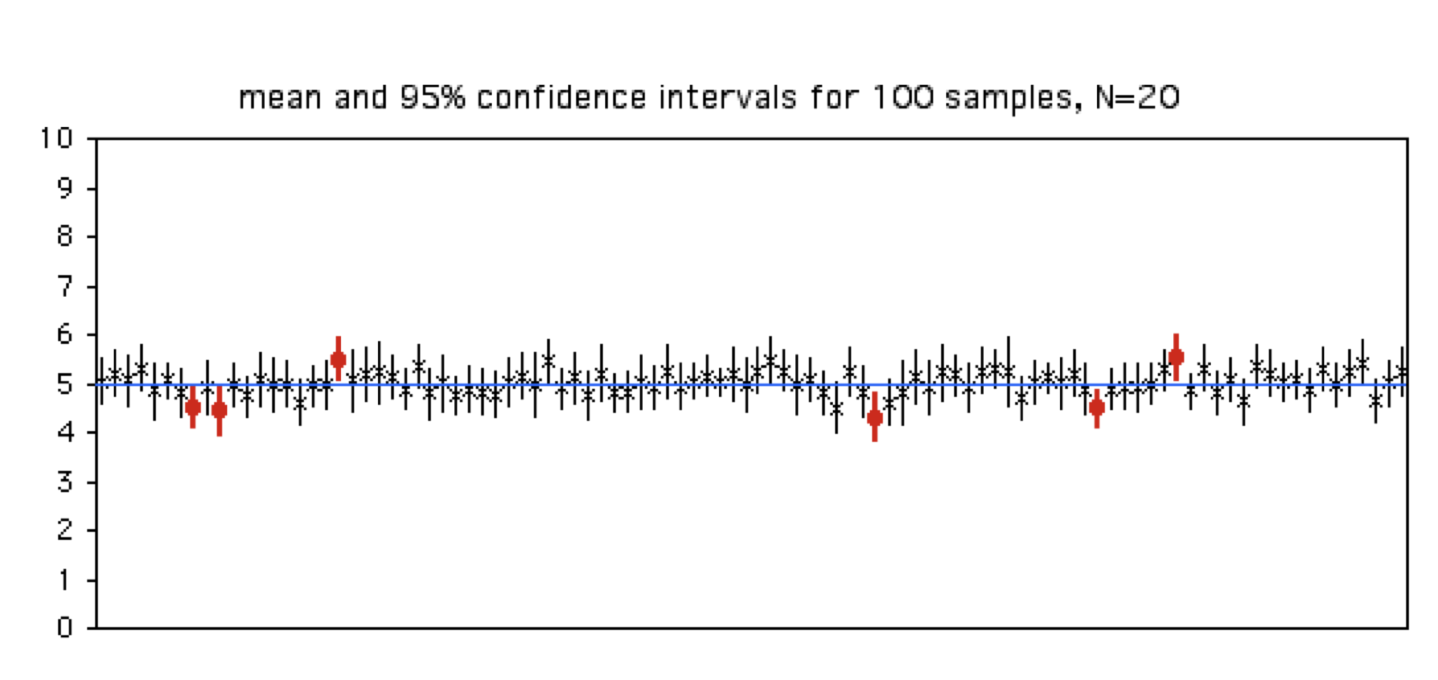
Dada esta descripción, es muy posible que quieras interpretarlos como “hay X% de probabilidad de que la estimación se encuentre en este intervalo”. NO SE INTERPRETAN DE ESA MANERA. La forma adecuada es, si realizo \(N\) muestreos independientes, cada uno con tamaño de muestra \(n\), y para cada uno estimo la media y sus intervalos de confianza, ≈ 95% de estas estimaciones incluirán la media “real” (poblacional; Figura 9.11).
Figura 9.11: Representación gráfica de la interpretación de los intervalos de confianza: 100 muestreos independientes con tamaño de muestra 20. Para cada uno se estima la media (x) y sus intervalos de confianza (líneas verticales). Solo seis (rojo) no incluyeron la media real (línea azul):
9.5.1 Cálculo de los intervalos de confianza
Te mencioné anteriormente que los IC siguen un modelo de distribución de probabilidades. Los modelos más comunes son las distribuciones \(t\) de Student y normal. Por el momento no es necesario que te preocupes por el modelo subyacente; sin embargo, lo más común es que utilicemos la distribución \(t\). ¿La razón? La veremos más adelante cuando expliquemos propiamente la pruena \(t\) de Student. Las ecuaciones correspondientes las puedes encontrar en un libro de estadística básica (e.g., Zar, 2010), así que te ahorraré el que las leas aquí y mejor vayamos directamente a cómo calcularlos con R.
Para ejemplificarlo utilicemos 15 muestras de nuestros 10,000 datos simulados bajo una distribución normal estándar (v1$var):
set.seed(0)v2 <-sample(v1$var, size =15)
La estimación de la media ya la conocemos. En este caso fue de -0.27, que podríamos decir se encuentra alejado de la media poblacional 0 que establecimos, pero ¿qué tanto es tantito? Es ahí donde entran los IC.
mean(v2)
[1] 0.3629882
Pero para calcularlos, posiblemente sin que sea sorpresa, tenemos distintas maneras de hacerlo. Comenzando con R base podemos utilizar la funciónt.test(x, conf.level), donde x es el vector de observaciones y conf.level el nivel de confianza deseado:
t.test(v2, conf.level =0.95)
One Sample t-test
data: v2
t = 1.3242, df = 14, p-value = 0.2067
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
-0.2249449 0.9509213
sample estimates:
mean of x
0.3629882
Esta función aplica una prueba \(t\) de Student para una sola muestra, por lo que da un valor del estadístico de prueba \(t\), los grados de libertad df y un valor de p. Por el momento olvidemos eso y quedémonos con el intervalo de confianza al 95%: \([-0.73, 0.18]\). Este intervalo es grande en relación a nuestra media (\(|IC_s - IC_i| = |0.18-0.73| = 0.55 > |\overline{x}| = 0.27\)), lo cual nos dice que no “confiamos” mucho en ese valor promedio, lo cual tiene sentido porque la distribución poblacional es una normal estandar (\(\mu = 0; \sigma = 1\)). Ahora bien, no podemos descartar que esa media sea diferente de 0, pues el IC incluye al 0 (ojo también al valor de p).
Tip
Tanto los IC como el valor de p pueden utilizarse para “probar hipótesis” (sensu pruebas de significancia). Si tus intervalos de confianza con amplitud \(1-\alpha\) para un efecto dado incluyen al 0, entonces vas a tener un valor de \(p > \alpha\).
Otra forma de calcularlos es con la función Rmisc::CI(x, ci), donde x es el vector de observaciones y ci el nivel de confianza:
Rmisc::CI(x = v2, ci =0.95)
upper mean lower
0.9509213 0.3629882 -0.2249449
Una alternativa más es utilizar la función rcompanion::groupwiseMean(formula, data, conf, R), la cual tiene dos funcionalidades interesantes: i) permite calcular los IC para varios grupos, y ii) poder estimar los intervalos a partir de remuestreos Bootstrap. En esta función: formula es lo que vimos en la función aggregate, donde indicamos al mismo tiempo la variable numérica y la variable de agrupamiento, tal que: var~grupo; data indica el data.frame que contiene la información, conf la amplitud de los intervalos y R el número de réplicas Bootstrap a realizar. Sustituyendo:
En formula pasamos v2~1, porque no tenemos una columna de agrupamiento (solo tenemos 1 grupo).
En data pasamos nuestro vector como un data.frame utilizando as.data.frame(v2).
En R pasamos NA para indicar que NO queremos que los IC se estimen utilizando réplicas Bootstrap.
Nota
Las réplicas Bootstrap son útiles cuando tenemos distribuciones muy sesgadas y no normales, a diferencia de nuestros datos de ejemplo. Cambia a R = 500. ¿Cambió algo?
Después de este pequeño rodeo en el cual vimos cómo los IC y los valores de p están íntimamente relacionados, volvamos a hablar de estos últimos y qué consideraciones debemos de tener al utilizarlos e interpretarlos.
9.6 Valores de p: usos y abusos
Dependiendo de cuántas veces hayas llevado una materia de estadística estarás más o menos familiarizado con la frase “No se encontraron diferencias significativas (\(p > \alpha = 0.05\)).” Pregunta: ¿de dónde salió ese \(\alpha = 0.05\)? Ojo, no te estoy preguntando qué representa \(\alpha\), sino de dónde salió el criterio de tomar 0.05 como el umbral para decidir si algo es significativo o no. Según qué tanto hayas leído (o qué tanto hayan hecho su tarea tus profesores), puedes dar una de tres respuestas:
“Porque así me lo enseñaron” (sensu convención).
“Porque es lo aceptado en el área de investigación” (idem).
“Porque así lo planteó Ronald Fisher, pues consideró que 1/20 falsos positivos eran pocos”.
Y las tres respuestas tienen algo de razón, pero también ambas están equivocadas. Me explico. Si bien es cierto que en el área de ecología y biología en general un \(\alpha\) de 0.05 se ha considerado como “suficiente”, justo porque estamos dispuestos a aceptar 1/20 falsos positivos, en otras áreas se requiere de mayor certeza para tomar una decisión. En el área de investigación médica y farmacéutica, por ejemplo, usualmente toman valores de 0.01 e, incluso, 0.001. La razón es que el nivel de \(\alpha\) debe de decidirse a priori, según el problema que tengamos entre manos y cuántos falsos positivos estemos dispuestos a aceptar.
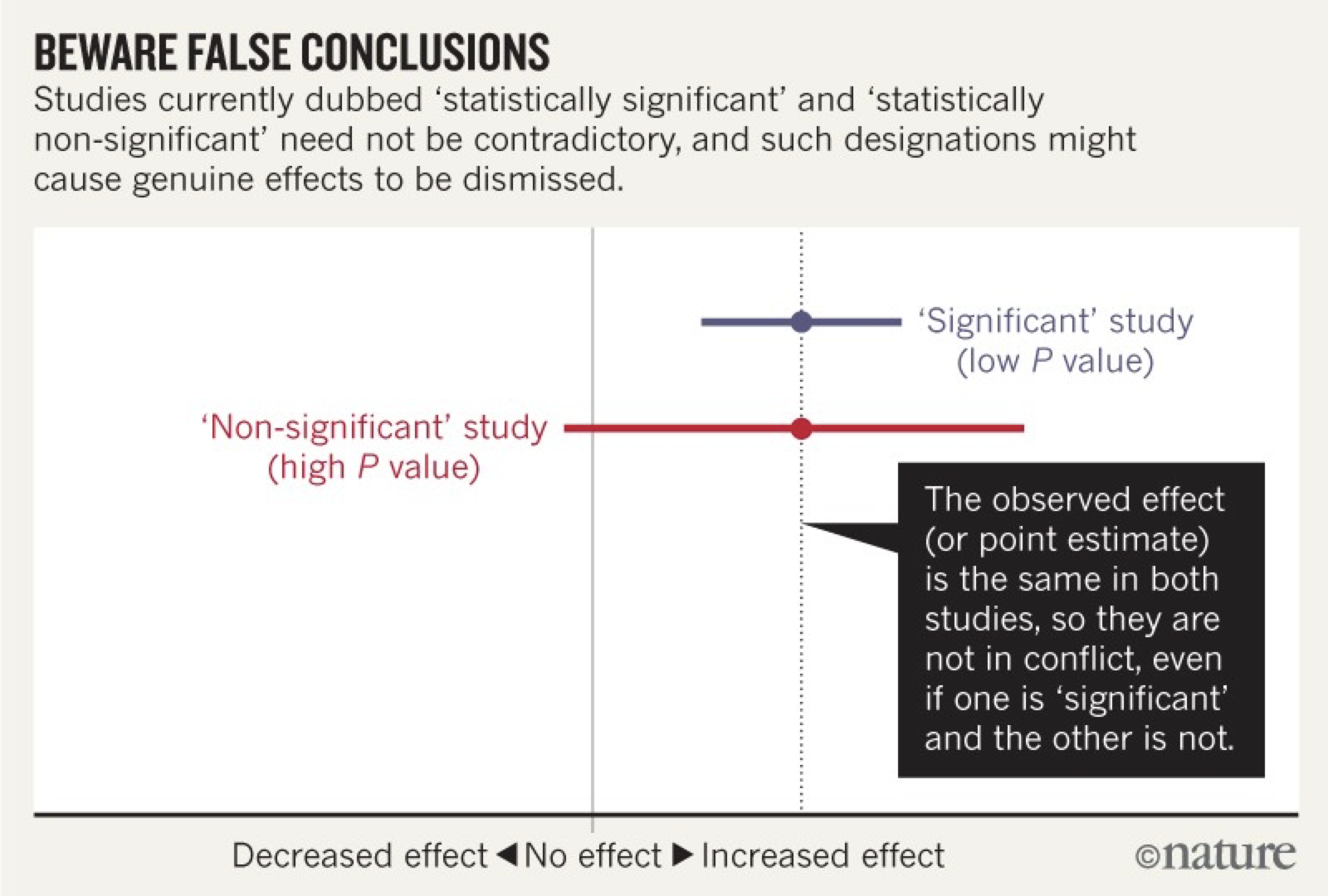
Figura 9.12: Valores de p, intervalos de confianza y conclusiones erróneas.
Aquí tenemos dos estudios que, en realidad, dieron resultados equivalentes o, cuando menos, que no están en conflicto uno con el otro. El estudio azul tuvo el mismo efecto positivo promedio que el rojo, aunque con un IC mucho más angosto y, en consecuencia, un valor de p “signficativo” (pequeño). El estudio rojo, por el contrario tiene un intervalo de confianza mucho más amplios que incluyeron el 0 y, consecuentemente, un valor de p “no significativo”. ¿Cuál sería la forma correcta de interpretar estos resultados? Primero, no descartar al estudio rojo o tacharlo de “no significativo”. Mejor, pensemos en los IC como intervalos de compatibilidad, describamos los resultados en función de las consecuencias de estos intervalos, con especial énfasis en la estimación puntual, pues es la más compatible con los datos. La razón de esto es que, por puro efecto del azar, el estudio azul podría replicar exactamente el mismo estudio y esta vez obteer un IC similar al rojo o viceversa.
Advertencia
¡Significancia estadística NO IMPLICA significancia biológica!
¿A qué me refiero con esta advertencia? A que no porque la prueba arroje efectos o diferencias significativas quiere decir que esas diferencias sean importantes para el fenómeno que estemos analizando y, de hecho, en la siguiente sesión vamos a ver un ejemplo donde la diferencia es muy pequeña en magnitud, pero es estadísticamente significativa. Sin más preámbulo, vayamos a aplicar una prueba de significancia.
9.7 Prueba básica: \(t\) de Student
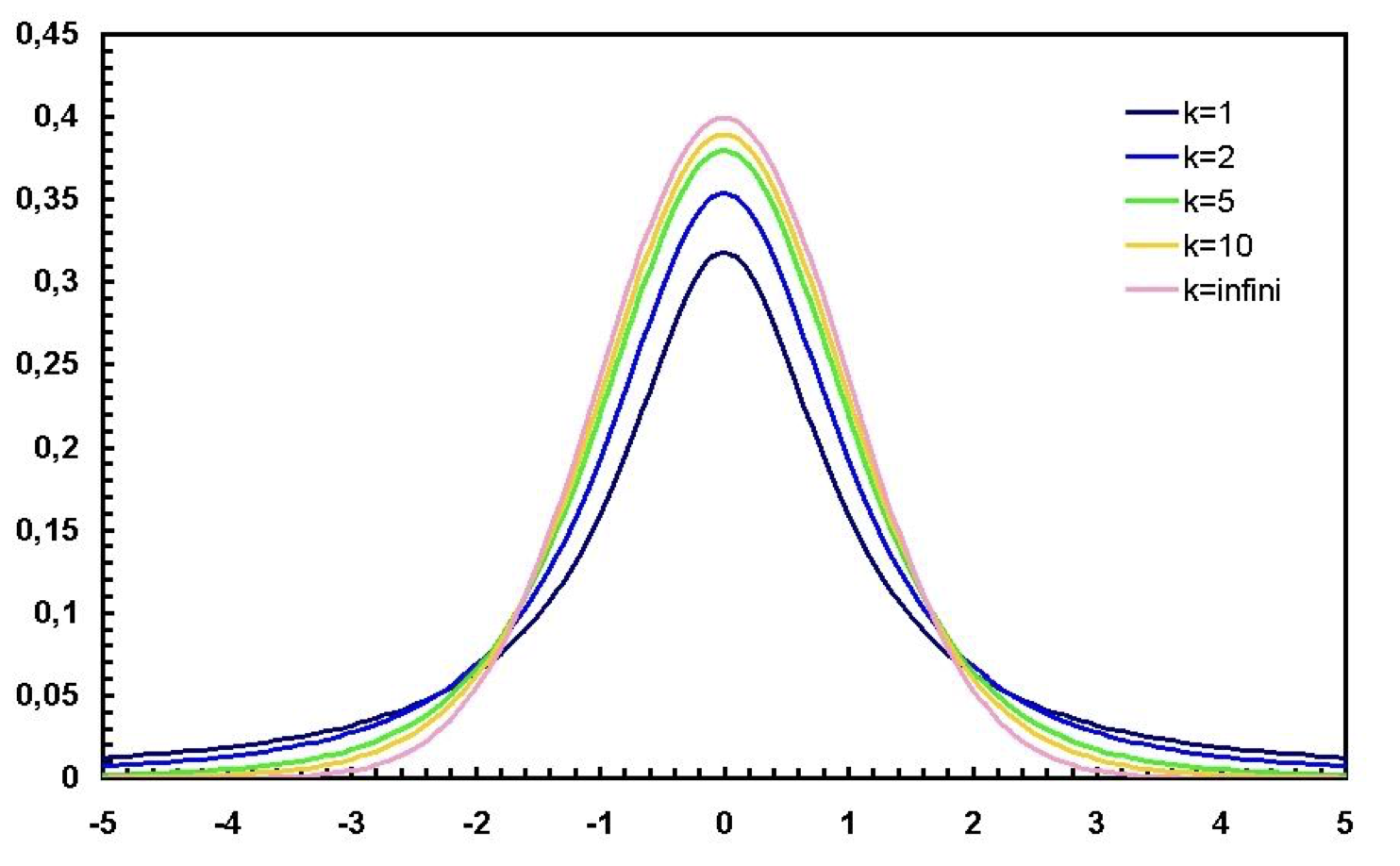
La prueba de hipótesis más conocida es la prueba \(t\) de Student, y con justa razón. Esta prueba se construye a partir de una distribución \(t\) de Student, la cual tiene tres parámetros: i) \(\mu\): media o centro de la distribución (posición del punto de mayor densidad en el eje x), ii) \(\sigma\): escala de la distribución (desviación estándar) y iii) \(\nu\): grados de libertad. Recordarás que los parámetros de una distribución afectan su forma. En este caso, el parámetro “más importante” son los grados de libertad, pues conforme estos se acerquen a infinito más se acercará la distribución a una normal. De hecho, con \(n \geq 30\) se considera que la distribución es prácticamente normal. ¿Qué es lo que cambia? La altura o el peso de las colas:
Figura 9.13: Distribución \(t\) de Student con diferentes grados de libertad \(k\) (\(\nu\)).
Este cambio en la altura de las colas es sumamente importante, y es lo que hace que la distribución \(t\) sea uno de los “caballitos de batalla” de la estadística, pues literalmente estamos siendo conscientes que, conforme disminuye el tamaño de muestra (grados de libertad, pero ahorita los definimos), incrementa la probabilidad de tener valores extremos (el peso de las colas). Con esto también establecemos que no queremos que esos valores extremos desvíen nuestras estimaciones.
En este punto estarás pensando “todo eso está muy bien, pero ¿qué son los grados de libertad y con qué se comen?” Y este concepto es uno que se entiende mejor si lo deducimos con un ejercicio extremadamente simple. Si yo te digo que obtengas el promedio de los números 1, 2 y 3 harías esto:
mean(c(1, 2, 3))
[1] 2
Y si te digo ahora que hagas eso mismo para los números 1 y 3:
mean(c(1, 3))
[1] 2
Obtenemos exactamente el mismo resultado que antes, pues retiramos la media del conjunto de datos original. Eso son los grados de libertad: el número de observaciones independientes de la media, tal que \(\nu = n - 1\). Es sumamente importante que tengas presente este concepto, pues un montón de pruebas involucran grados de libertad.
Nota
En algunas pruebas verás que los grados de libertad se estiman de distintas maneras, según qué involucre la prueba y qué grados de libertad sean los que se están calculando, pero la escencia siempre es la misma: retirar la media de los datos.
Volviendo a la prueba \(t\), tenemos dos variantes y media: una prueba para una muestra, una para dos muestras independientes o una para dos muestras dependientes. ¿Por qué dos variantes y media? Ya lo verás con el caso de dos muestras dependientes (pareadas). En general, esta prueba nos permite comparar dos valores (un promedio contra una referencia o dos promedios). Sus supuestos son:
Normalidad (si son dos grupos cada grupo debe de estar normalmente distribuido)
Muestras independientes; es decir que la observación \(x_i\) sea independiente de la observación \(x_j\), que es diferente de tener muestras pareadas.
Homogeneidad de varianzas.
Nota
En la siguiente sesión hablaremos largo y tendido de estos supuestos, pero por el momento entiéndelos como “requisitos” o “características” que deben de tener nuestros datos para que podamos confiar en los resultados de la prueba.
Adicionalmente se “recomienda” que se utilice con tamaños de muestra menores a 30, por aquello de que a partir de 30 la distribución se vuelve prácticamente normal, pero también es recomendada si no conocemos la varianza poblacional.
9.7.1 Prueba \(t\) para una muestra
Esta prueba nos permite comparar la media de una muestra con un valor de referencia. La función de la prueba \(t\) para una muestra está dada por:
\[
t = \frac{\overline{x}- \mu_0}{\frac{s}{\sqrt{n}}}
\] Donde: \(\overline{x}\) es el promedio de nuestra muestra, \(\mu_0\) es un valor de referencia con el que queremos comparar \(\overline{x}\), \(s\) es la desviación estándar de la muestra y \(n\) es el número de observaciones. Esta ya la aplicamos antes cuando estimamos los intervalos de confianza con la función t.test, pero volvamos a visitarla:
t.test(v2, mu =0, conf.level =0.95)
One Sample t-test
data: v2
t = 1.3242, df = 14, p-value = 0.2067
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
-0.2249449 0.9509213
sample estimates:
mean of x
0.3629882
Ahora sí podemos revisar la salida completa. La primera línea nos dice el tipo de prueba \(t\) que estamos aplicando. En este caso pasamos un solo vector, por lo que la prueba a aplicar es para una sola muestra. La segunda línea nos da el nombre de los datos. La tercera nos da los resultados de la prueba: el valor del estadístico \(t\), los grados de libertad d.f. (degrees of freedoom) y el valor de p (p-value), mientras que la cuarta nos da la hipótesis alternativa que estamos evaluando (la nula no cambia, ¿o sí?) ¿Contra qué valor está contrastando? Por defecto contra 0 (podemos cambiarlo con el argumento mu).
¿Cómo reportamos estos resultados? “La media no fue signficativamente diferente de 0 (\(t = -1.29\), \(d.f. = 14\), \(p = 0.21 > \alpha = 0.05\)).
Importante
Siempre que hagas una prueba estadística es importante reportar el valor del estadístico de prueba y el/los parámetro(s) de la distribución, además del valor de p. ¿La razón? Para allá vamos.
Ahora bien, ¿por qué da una hipótesis alternativa? Porque podemos probar una de tres:
La media es diferente de \(\mu_0\), en donde se aplica una prueba de dos colas.
La media es menor a \(\mu_0\), en donde se aplica una prueba de una sola cola (considera la cola derecha).
La media es mayor a \(\mu_0\), en donde se aplica también una prueba de una cola (la cola izquierda)
Lo cual me lleva a hablar de pruebas de dos o una cola. El qué hipótesis alternativa se prueba ya lo definimos, pero ¿a qué se refiere eso de una o dos colas? A qué cola(s) integramos. En la Figura 9.10 vimos que sumabamos lo que estaba fuera de nuestra área de aceptación, tanto a la derecha como a la izquierda; es decir, las colas de la distribución. Si solo sumamos lo que está a la derecha estamos preguntándonos si nuestra media es menor a \(\mu_0\).
Esto podemos modificarlo con el argumento alternative, que puede ser "two.sided" (por defecto), "greater" o "less". Veamos el resultado con la hipótesis alternativa de que la media es menor a 0:
t.test(v2, conf.level =0.95, alternative ="greater")
One Sample t-test
data: v2
t = 1.3242, df = 14, p-value = 0.1033
alternative hypothesis: true mean is greater than 0
95 percent confidence interval:
-0.1198256 Inf
sample estimates:
mean of x
0.3629882
Aquí, además de la hipótesis alternativa, hay dos cambios que es importante notar: el valor de p y el intervalo de confianza. Empecemos con el segundo, donde tenemos [-Inf, 0.099]. Esto no es ningún error. Simple y sencillamente refleja nuestra hipótesis alternativa: Si la media es menor no tiene caso que consideremos la cola izquierda, por lo que el límite inferior se va a -Inf, mientras que el límite superior se reduce a 0.099. Compara ese valor de 0.099 con el resultado de la prueba de dos colas. ¿Qué notas? Es exactamente la mitad. Estos intervalos de confianza son simétricos, por lo que si solo estamos considerando un lado es lógico que la amplitud se reduzca a la mitad y eso me lleva al otro cambio: el valor de p. También es exactamente la mitad del que nos dio la prueba para dos colas, y es por la misma razón, estamos considerando la mitad del área bajo la curva. Pero aquí hay una advertencia muy, pero muy importante:
Advertencia
La decisión de si se aplica una prueba de una o dos colas es algo que se realiza a priori; es decir, desde un inicio seleccionamos nuestra hipótesis alternativa. No se vale aplicar la prueba de dos colas (hay diferencias significativas), ver que nuestro valor de p > 0.05, pero no es tan grande y luego aplicar una prueba de una cola para forzar un resultado significativo.
Esta es la razón por la que hay que reportar la prueba, el valor del estadístico de prueba, los parámetros involucrados y el valor de p: podemos verificar que el resultado corresponda con la hipótesis que se dice se está probando. Me ha tocado saber de casos donde en la sección de métodos ponen la hipótesis alternativa en términos de “es diferente” (prueba de dos colas) y a la hora de presentar los resultados quieren “colar” una prueba de una cola. Pensemos que alguien nos dice en la sección de métodos: “Para evaluar si la media de la variable X fue significativamente diferente de 0 se utilizó una prueba \(t\) de Student (\(\alpha = 0.05\))”, y en los resultados: “La media fue significativamente diferente de 0 (\(\mu = 0.25; SD = 0.2\); t = -1.7, df = 14, p = 0.027). Ese valor de t es”grande”, pero no lo suficiente para dar un valor de p tan “lejano” de 0.05, por lo que nos damos a la tarea de corroborarlo:
pt(q =-1.7, df =14)
[1] 0.05561478
¡Sorpresa! El valor sí que era más pequeño (la mitad), por lo que esta persona aplicó una prueba de una cola y quiso darla como una prueba de dos colas. Otra forma de hacerlo sería comprobar el valor de t que le correspondería a ese valor de p:
qt(p =0.027, df =14)
[1] -2.103324
Moraleja: dejemos las pruebas de una sola cola para cuando realmente sea nuestro interés probar si algo es mayor o menor que otra cosa que, te adelanto, son muy pocos casos en donde tenemos suficiente información para sospechar eso desde nuestro diseño experimental.
9.7.2 Prueba para muestras independientes
La siguiente variación la tenemos cuando queremos comparar las medias de dos muestras independientes o, mejor dicho, dos grupos independientes. Es decir, los individuos que forman al grupo 1 son diferentes de los que conforman al grupo 2. La ecuación original sufre una ligera modificación, en donde ahora se considera la desviación estándar mancomunada (\(sp\)) de las muestras; es decir, la variación en el valor dada por ambos grupos. Esto es importante, pues no es lo mismo tener una diferencia promedio de 10g con una desviación mancomunada de 100 g a tener esos mismos 10g de diferencia con una desviación mancomunada de 10g. La función queda entonces:
\[
t = \frac{\overline{x_1} - \overline{x_2}}{sp\cdot\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}}
\]
Afortunadamente para implementarla en R solo vamos a utilizar la función t.test(formula, data) que ya conocíamos, solo que añadiremos dos argumentos adicionales: var.equal = T y paired = F. var.equal hace referencia al supuesto de homogeneidad de varianzas que mencionamos antes. Si no se cumple podemos pasar var.equal = F y entonces se aplicará la prueba \(t\) de Welch, la cual modifica el modo en el que se estima la varianza mancomunada y permite contender con varianzas desiguales. paired, por otra parte, define si es una prueba para muestras independientes (F) o muestras dependientes (pareadas, T). Esto último lo veremos más adelante.
Nota
¿Qué prueba aplicar? ¿\(t\) de Welch o \(t\) de Student? Por defecto la función t.test aplica la prueba de Welch, la cual es más poderosa que la de Student cuando no se cumple el supuesto de homogeneidad de varianzas y al menos tan poderosa como la de Student cuando se cumplen todos sus supuestos. La decisión es tuya, pero la prueba \(t\) de Welch cubre la mayor parte de los casos.
Creemos primero un conjunto de datos y luego apliquemos la prueba:
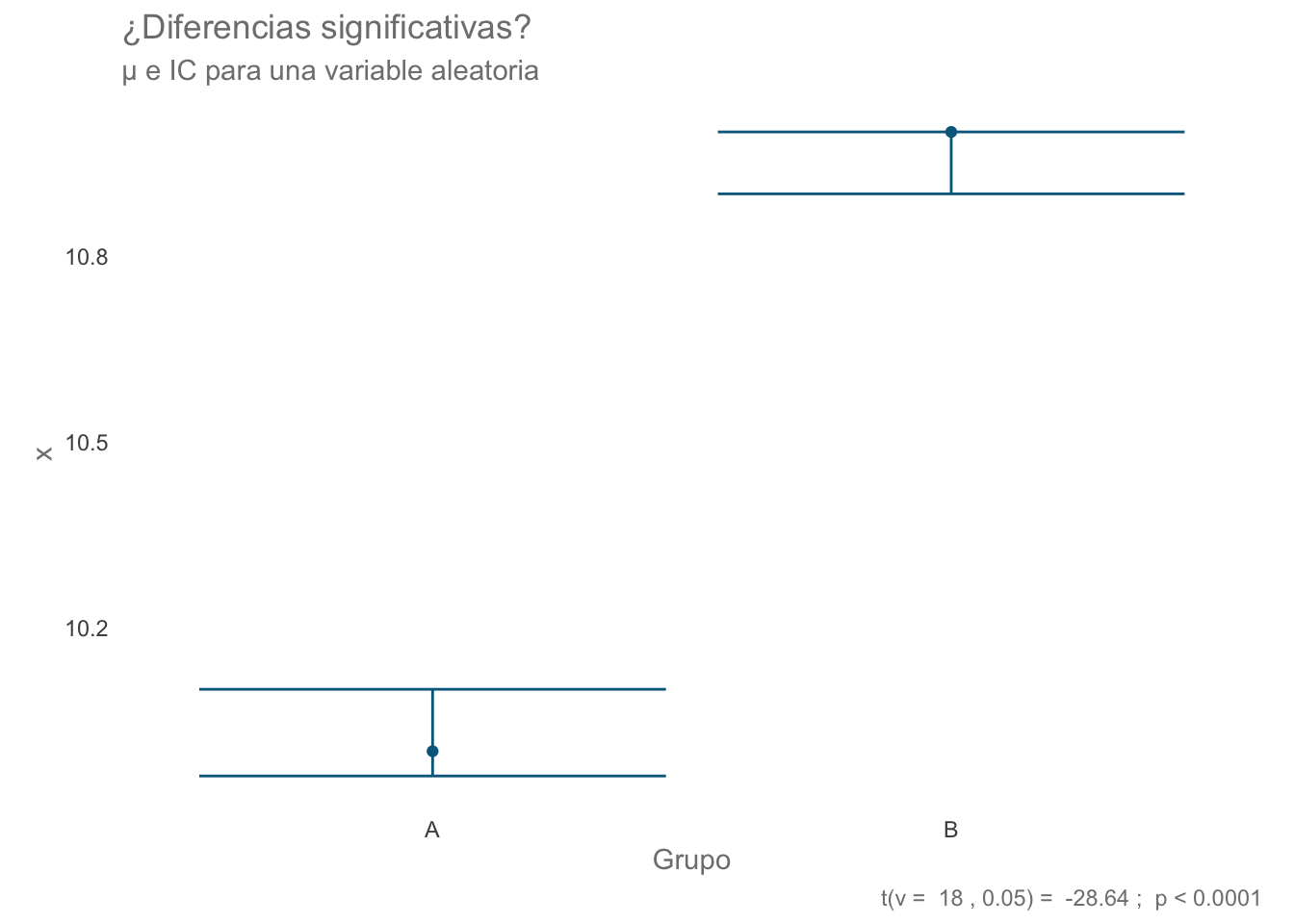
# Datos del grupo AA <-rnorm(10, 10, 0.1)# Datos del grupo BB <-rnorm(10, 11, 0.1)# Formar un solo data.framedf1 <-data.frame(grupo ="A", v1 = A)df1 <-rbind(df1, data.frame(grupo ="B", v1 = B))# Aplicar la pruebat.test(v1~grupo, data = df1, var.equal = T, paired = F)
Two Sample t-test
data: v1 by grupo
t = -28.643, df = 18, p-value < 2.2e-16
alternative hypothesis: true difference in means between group A and group B is not equal to 0
95 percent confidence interval:
-1.0535072 -0.9095223
sample estimates:
mean in group A mean in group B
10.00929 10.99081
La salida es muy parecida al caso anterior: el tipo de prueba, el valor del estadístico de prueba, los grados de libertad, el valor de p, la hipótesis alternativa, un intervalo de confianza y los promedios de cada grupo. ¿Qué representa ese intervalo de confianza? Es el intervalo de confianza para la diferencia de medias, que es el cómo estamos comparando los grupos.
Podemos también presentar los resultados de manera gráfica. Para ello necesitaremos guardar los resultados de nuestra prueba t.test en un objeto y extraer la información de ahí. ¿Cómo verificamos cuál es el tipo de objeto?
El objeto es una lista NOMBRADA, por lo que podemos acceder a su contenido utilizando el operador de [[]] (posición numérica o "nombre") o el operador $. Guardemos el valor de p en un nuevo objeto para incluirlo en la gráfica:
p_val <- ttest$p.valuep_val
[1] 1.814597e-16
Construyamos y grafiquemos los intervalos de confianza para la media de cada grupo (95%):
Esta prueba nos permite comparar los promedios de una variable de un mismo grupo en dos momentos diferentes en el tiempo, por ejemplo, comparar si la frecuencia cardiaca promedio de un grupo de participantes fue diferente antes y después de hacer ejercicio; es decir tendremos datos pareados cuando tengamos mediciones de los mismos individuos (identificados) en dos momentos diferentes. La prueba para muestras pareadas es la media variante que mencioné al inicio. ¿Por qué media? Porque en realidad aplica la prueba de una sola muestra, solo que con un paso previo: restamos los valores de cada individuo para quedarnos con un solo vector de diferencias y con ese aplicar la prueba para una muestra:
\[
t = \frac{\overline{X}_D - \mu_o}{\frac{S_D}{\sqrt n}}
\]
Donde \(\overline{X_D}\) y \(S_D\) son el promedio y la desviación estándar de las diferencias. Hagamos el ejercicio. Primero, carguemos los datos, que en este caso están contenidos en un archivo de excel:
t.test(FC~periodo, data = dependientes_m, paired = T)
Paired t-test
data: FC by periodo
t = -6.1115, df = 9, p-value = 0.0001768
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-24.11459 -11.08541
sample estimates:
mean difference
-17.6
Como era de esperarse, hubo diferencias en la frecuencia cardiaca. Ahora comprobemos que solo se hizo la resta de inicial vs final:
One Sample t-test
data: dif_FC
t = 6.1115, df = 9, p-value = 0.0001768
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
11.08541 24.11459
sample estimates:
mean of x
17.6
9.8 Ejercicio
En esta sesión hay dos ejercicios:
Carga el archivo Datos1 2.csv (ojo con los nombres de las columnas al cargarlo) y realiza la estimación de la media, la desviación estándar y los intervalos de confianza (calquiera de las formas) para al menos 3 tamaños de muestra diferentes (considera que tienes la población completa). El objetivo es que veas y describas cómo cambian tanto la estimación puntual como la amplitud de los intervalos de confianza al incrementar el tamaño de muestra. Puedes utilizar cualquiera de las variables LT o PT.
Realiza la prueba t con los datos de la hoja 1 del archivo datos_t.xlsx, la cual contiene datos de dos muestras independientes. La tarea consiste en cargar los datos, realizar la prueba y presentar un gráfico en el que se reporten los resultados.
Armhein V, Greenland S, McShane B. 2019. Scientists rise up against statistical significance. Nature 567:305-307. DOI: 10.1038/d41586-019-00857-9.
Savage LJ. 1954. The Foundations of Statistics. John Wiley & Sons.